

Link to workbook for this week:
Overview
Recall that psychology begins with a question. What do I want to know about thought and behaviour? In cross-cultural psychology, these questions relate to differences, and similarities, between groups.
Suppose we have asked a question. How can we address it using observational data?
Too fast.
Our question must be made precise.
Today we will consider how to make psychological questions precise, and how to answer them, using 3-wave panel designs (VanderWeele, Mathur, and Chen 2020).
The order is as follows:
- Motivate Three Wave Longitudinal Designs Using Causal Graphs
- Checklist For Causal Estimation in Three Wave Longitudinal Designs
- Explanation of the the Checklist
Let’s dive in!
Motivations for a Three-Wave Longitudinal Design for Observational Causal Inference.
REVIEW: Causal Diagrammes (DAGS) are a remarkably powerful and simple tool for understanding confounding https://go-bayes.github.io/psych-434-2023/content/common_graphs.html
Common cause of exposure and outcome.
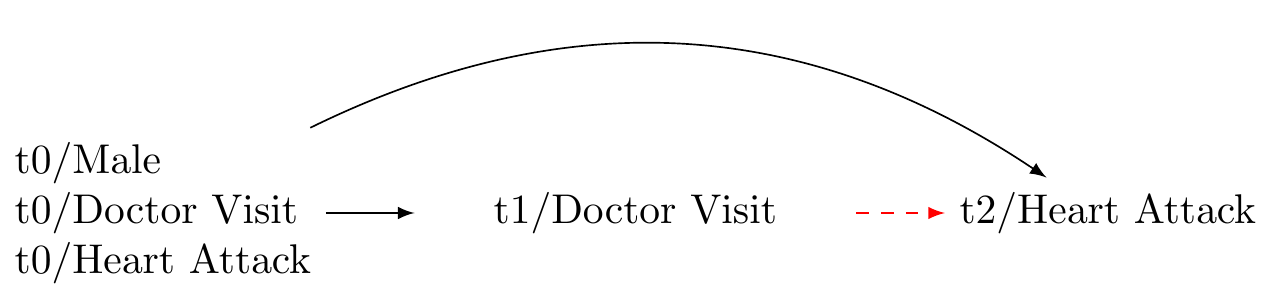
Our question: does visiting a clinical psychologist reduce the 10 year incidence of heart attacks?
Solution: Adjust for Confounder

Bias: exposure at baseline is a common cause of the exposure at t1 and outcome at t2

Solution: adjust for confounder at baseline

A more thorough confounding control
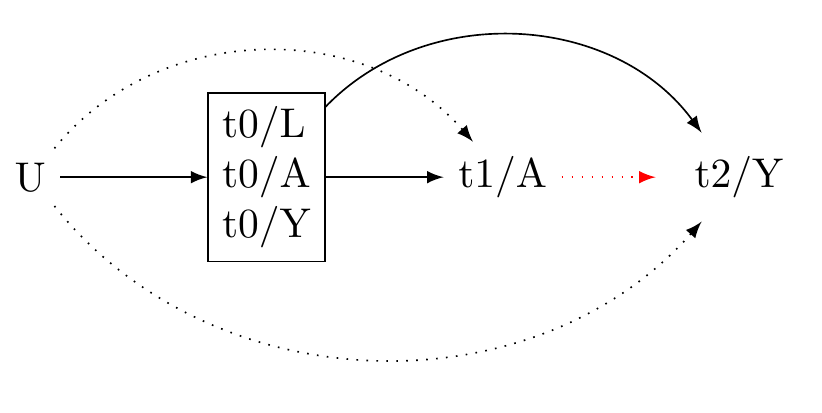
Generic 3-wave panel design (VanderWeeele 2020)
Comprehensive Checklist for Detailed Reporting of a Causal Inferenctial Study (E.g. Assessment 3 option 2)
STEP 1 Formulate the Research Question
- Stating the Question: Is my question clearly stated? If not, state it.
- Relevance of the Question: Have I explained its importance? If not, explain.
- Ethical Considerations How might this question affect people? How might not investigating this question affect people?
- Causality of the Question: Is my question causal? If not, refine your question.
- Subgroup Analysis: Does my question involve a subgroup (e.g., cultural group)? If not, develop a subgroup analysis question.
- Understanding the Framework: Can I explain the potential outcomes framework, individual causal effects, the experimental method to obtain average causal effects, the fundamental assumptions of causal inference, and the estimation of causal effects in observational data? If not, review course materials.
Data Requirements
- Type of Data: Are my data experimental? If yes, your project may not fit this course.
- Time-Series Data: Are my data time-series? If not, reconsider your causal question.
- Data Waves: Do I have at least three waves of data? If not, beware of confounding control issues.
- Data Source: Are my data from the NZAVS simulated data set? If not, consult with me.
Defining the Outcome
- Outcome Variable: Is the outcome variable Y defined? If not, define it.
- Multiple Outcomes: Are there multiple outcomes? If yes, write them down.
- Outcome Relevance: Can I explain how the outcome variable/s relate to my question? If not, clarify.
- Outcome Type: Is my outcome binary and rare? If yes, consider logistic regression. If my outcome is continuous, consider z-transforming it or categorising it (consult an expert).
- Outcome Timing: Does the outcome appear after the exposure? It should.
Determining the Exposure
- Exposure Variable: Is the exposure variable A defined? If not, define it.
- Multiple Exposures: Are there multiple exposures? If yes, reassess; if only one exposure, proceed.
- Exposure Relevance: Can I explain how the exposure variable relates to my question? If not, clarify.
- Positivity: Can we intervene on the exposure at all levels of the covariates? We should be able to.
- Consistency: Can I interpret what it means to intervene on the exposure? I should be able to.
- Exchangeability: Are different versions of the exposure conditionally exchangeable given measured baseline confounders? They should be.
- Exposure Type: Is the exposure binary or continuous? If continuous, z-transform it or consider categorising it (consult an expert).
- Exposure Timing: Does the exposure appear before the outcome? It should.
Accounting for Confounders
- Baseline Confounders: Have I defined my baseline confounders L? I should have.
- Justification: Can I explain how the baseline confounders could affect both A and Y? I should be able to.
- Timing: Are the baseline confounders measured before the exposure? They should be.
- Inclusion: Is the baseline measure of the exposure and the baseline outcome included in the set of baseline confounders? They should be.
- Sufficiency: Are the baseline confounders sufficient to ensure balance on the exposure, such that A is independent of Y given L? If not, plan a sensitivity analysis.
- Confounder Type: Are the confounders continuous or binary? If so, consider converting them to z-scores. If they are categorical with three or more levels, do not convert them to z-scores.
Drawing a Causal Diagram with Unmeasured Confounders
- Unmeasured Confounders: Does previous science suggest the presence of unmeasured confounders? If not, expand your understanding.
- Causal Diagram: Have I drawn a causal diagram (DAG) to highlight both measured and unmeasured sources of confounding? I should have.
- M-Bias: Have I considered the possibility of M-Bias? If not familiar, we’ll discuss later.
- Measurement Error: Have I described potential biases from measurement errors? If not, we’ll discuss later.
- Temporal Order: Does my DAG have time indicators to ensure correct temporal order? It should.
- Time Consistency: Is my DAG organized so that time follows in a consistent direction? It should.
Identifying the Estimand
- Causal Estimand: Is my causal estimand one of the following:
ATE_{G,(A,A')} = E[Y(1) - Y(0)|G, L]
ATE_{G,(A/A')} = \frac{E[Y(1)|G, L]}{E[Y(0)|G, L]}
If yes, you’re on the right track.
Understanding Source and Target Populations
- Populations Identified: Have I differentiated between my source and target populations? I should have.
- Generalisability and Transportability: Have I considered whether my results generalise to the source population and transport to a different population? I should have.
Setting Eligibility Criteria
- Criteria Stated: Have I stated the eligibility criteria for the study? I should have.
Describing Sample Characteristics
- Descriptive Statistics: Have I provided descriptive statistics for demographic information taken at baseline? I should have.
- Exposure Change: Have I demonstrated the magnitudes of change in the exposure from baseline to the exposure interval? I should have.
- References: Have I included references for more information about the sample? I should have.
Addressing Missing Data
- Missing Data Check: Have I checked for missing data? I should have.
- Missing Data Plan: If there is missing data, have I described how I will address it? I should have.
Selecting the Model Approach
- Approach Decision: Have I decided on using G-computation, IPTW, or Doubly-Robust Estimation? I should have.
- Interaction Inclusion: Have I included the interaction of the exposure and baseline covariates? I should have.
- Large Data Set: If I have a large data set, should I include the interaction of the exposure, group, and baseline confounders? I should consider it.
- Model Specification: Have I double-checked the model specification? I should.
- Outcome Specifics: If the outcome is rare and binary, have I specified logistic regression? If it’s continuous, have I considered converting it to z-scores?
- Sensitivity Analysis: Am I planning a sensitivity analysis using simulation? If yes, describe it (e.g. E-values.)
d. Highlight unmeasured pre-treatment covariates
Let U denoted unmeasured pre-treatment covariates that may potentially bias the statistical association between A and Y independently of the measured covariates.
Consider:
- To affect Y and A, U must occur before A.
- It is useful to draw a causal diagramme to illustrate all potential sources of bias.
- Causal diagrammes are qualitative tools that require specialist expertise. We cannot typically obtain a causal graph from the data.
- A causal diagramme should include only as much information as is required to assess confounding. See Figure 7 for an example.
- Because we cannot ensure the absence of unmeasured confounders in observational settings, it is vital to conduct sensitivity analyses for the results. For sensitivity analyeses, we use E-values, a topic for a latter seminar.
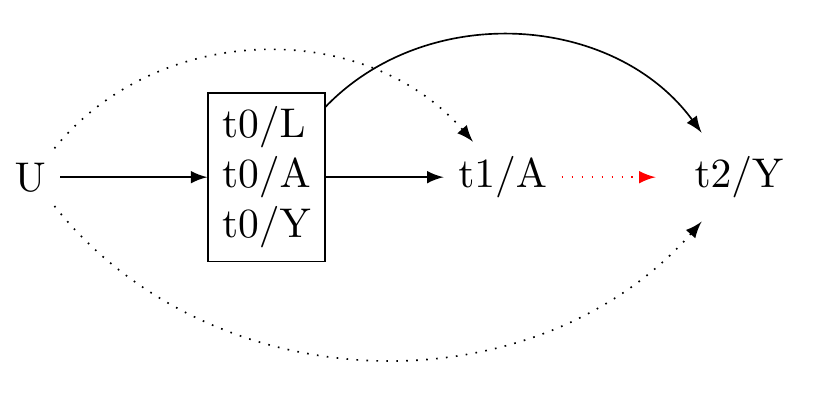
e. Choose the scale for a causal contrast
Average causal effects can be inferred by contrasting the expected outcome when a population is exposed to an exposure level, E[Y(A = a)], with the expected outcome under a different exposure level, E[Y(A=a')].
For a binary treatment with levels A=0 and A=1, the Average Treatment Effect (ATE), on the difference scale, is expressed:
ATE_{\text{risk difference}} = E[Y(1)|L] - E[Y(0)|L]
On the risk ratio scale, the ATE is expressed:
ATE_{\text{risk ratio}} = \frac{E[Y(1)|L]}{E[Y(0)|L]}
Other effect scales, such as the incidence rate ratio, incidence rate difference, or hazard ratio, might also be of interest. We can also define the Average Treatment Effect on the Treated (ATT) :
ATT_{\text{risk difference}} = E[Y(1) - Y(0)|A=1,L]
ATT_{\text{risk ratio}} = \frac{E[Y(1)|A=1,L]}{E[Y(0)|A=1, L]}
Another common estimand is the Population Average Treatment Effect (PATE), which denotes the effect the treatment would have on the entire population if applied universally to that population. This quantity can be expressed:
PATE_{\text{risk difference}} = f(E[Y(1) - Y(0)|L], W)
PATE_{\text{risk ratio}} = f\left(\frac{E[Y(1)|L]}{E[Y(0)|L]}, W\right)
where f is a function that incorporates weights W into the estimation of the expected outcomes. These weights are given from census estimates for the wider population. Note: I will show you how to use weights in future seminars.
We might also be interested in identifying effects specific to certain strata, such as risk differences or risk ratios, as they are modified by baseline indicators. Denote a stratum of interest by G. We may then compute:
ATE_{G,\text{risk difference}} = E[Y(1) - Y(0)|G, L]
ATE_{G,\text{risk ratio}} = \frac{E[Y(1)|G, L]}{E[Y(0)|G, L]}
Consider:
- In this course, we are interested in stratum specific comparisons
- In the causal inference literature, the concept we use to make sense of stratum specific comparisons is called “effect modification.”
- By inferring effects within stratums, we may evaluate whether the effects of different exposures or treatments on some well-defined outcome (measured in some well-defined time-period after the exposure) differ depending on group measurement.
- The logic of effect modification differs slightly from that of interaction.
Aside: extensions
For continuous exposures, we must stipulate the level of contrast for the exposure (e.g. weekly versus monthly church attendance):
ATE_{A,A'} = E[Y(A) - Y(A')| L]
This essentially denotes an average treatment effect comparing the outcome under treatment level A to the outcome under treatment level A'.
Likewise:
ATE_{A/A'} = \frac{E[Y(A)| L]}{E[Y(A')| L]}
This defines the contrast of A and A' on a ratio scale.
f. Describe the population(s) for whom the intended study is meant to generalise by distinguishing between source and target populations.
Consider the following concepts:
Source population: A source population is where we gather our data for a study. We pull our specific sample from this group. It needs to mirror the broader group for our conclusions to be valid and widely applicable.
Target population: The target population is the larger group we aim to apply our study’s results to. It could be defined by location, demographics, or specific conditions. The closer the source matches the target in ways that are relevant to our causal questions, the stronger our causal inferences about the target population will be.
- Generalisability refers to the ability to apply the causal effects estimated from a sample to the population it was drawn from. In simpler terms, it deals with the extrapolation of causal knowledge from a sample to the broader population. This concept is also called “external validity”.
\text{Generalisability} = PATE \approx ATE_{\text{sample}}
- Transportability refers to the ability to extrapolate causal effects learned from a source population to a target population when certain conditions are met. It deals with the transfer of causal knowledge across different settings or populations.
\text{Transportability} = ATE_{\text{target}} \approx f(ATE_{\text{source}}, T)
where f is a function and T is a function that maps the results from our source population to another population. To achieve transportability, we need information about the source and target populations and an understanding of how the relationships between treatment, outcome, and covariates differ between the populations. Assessing transportability requires scientific knowledge.
Summary Step 1: Consider how much we need to do when asking a causal question!
We discover that asking a causal question is a multifaceted task. It demands careful definition of the outcome, including its timing, the exposure, and covariates. It also requires selecting the appropriate scale for causal contrast, controlling for confounding, and potentially adjusting for sample weights or stratification. Finally, when asking a causal question, we must consider for whom the results apply. Only after following these steps can we then ask: “How may we answer this causal question?”
STEP 2: ANSWER A CAUSAL QUESTION
Obtain longitudinal data
Note that causal inference from observational data turns on the appropriate temporal ordering of the key variables involved in the study.
Recall we have defined.
A: Our exposure or treatment variable, denoted as A. Here we consider the example of ‘Church attendance’.
Y: The outcome variable we are interested in, represented by Y, is psychological distress. We operationalise this variable through the ‘Kessler-6’ distress scale.
L: The confounding variables, collectively referred to as L, represent factors that can independently influence both A and Y. For example, socio-economic status could be a confounder that impacts both the likelihood of church attendance and the levels of psychological distress.
Given the importance of temporal ordering, we must now define time:
- t \in T: Let t denote within a multiwave panel study with T measurement intervals.
Where t/\text{{exposure}} denotes the measurement interval for the exposure. Longitudinal data collection provides us the ability to establish a causal model such that:
t_{confounders} < t_{exposure}< t_{outcome}
To minimise the posibility of time-varying confounding and obtain the clearest effect estimates, we should acquire the most recent values of \mathbf{L} preceding A and the latest values of A before Y.
Note in Figure 7, We use the prefixes “t0, t1, and t2” to denote temporal ordering. We include in the set of baseline confounders the pre-exposure measurement of A and Y. This allows for more substantial confounding control. For unmeasured confounder to affect both the exposure and the outcome, it would need to do so independently of the pre-exposure confounders. Additionally, including the baseline exposure gives us an effect estimate for the incidence exposure, rather than the prevelance of the exposure. This helps us to assess the expected change in the outcome were we to initate a change in the exposure.
Include the measured exposure with baseline covariates
Controlling for prior exposure enables the interpretation of the effect estimate as a change in the exposure in a manner akin to a randomised trial. We propose that the effect estimate with prior control for the exposure estimates the “incidence exposure” rather than the “prevalence exposure” (Danaei, Tavakkoli, and Hernán 2012). It is crucial to estimate the incidence exposure because if the effects of an exposure are harmful in the short term such that these effects are not subsequently measured, a failure to adjust for prior exposure will yield the illusion that the exposure is beneficial. Furthermore, this approach aids in controlling for unmeasured confounding. For such a confounder to explain away the observed exposure-outcome association, it would need to do so independently of the prior level of the exposure and outcome.
State the eligibility criteria for participation
This step is invaluable for assessing whether we are answering the causal question that we have asked.
Consider:
- Generalisability: we cannot evaluate inferences to a target group from the source population if we do not describe the source population
- Eligibility criteria will help us to ensure whether we have correctly evaluated potential measurement bias/error in our instruments.
For example, the New Zealand Attitudes and Values Study is a National Probability study of New Zealanders. The details provided in the supplementary materials describe how individuals were randomly selected from the country’s electoral roll. From these invitations there was typically less than 15% response rate. How might this process of recruitment affect generalisability and transportability of our results?
- Aside: discuss per protocol effects/ intention to treat effects
Determine how missing data will be handled
- As we will consider in the upcoming weeks, loss to follow up and non-response opens sources for bias. We must develop a strategy for handling missing data.
State a statistical model
The models we have considered in this course are G-computation, Inverse Probability of Treatement Weighting, and Doubly-Robust estimation.
Reporting
Consider the following ideas about how to report one’s model:
- Estimator: Doubly robust where possible.
- Propensity Score Reporting: Detail the process of propensity score derivation, including the model used and any variable transformations.
- WeightIt Package Utilisation: Explicitly mention the use of the ‘WeightIt’ package in R, including any specific options or parameters used in the propensity score estimation process.
- Method Variations: Report if different methods were used to obtain propensity scores, and the reasons behind the choice of methods such as ‘ebal’, ‘energy’, and ‘ps’.
- Continuous Exposures: Highlight that for continuous exposures, only the ‘energy’ option was used for propensity score estimation.
- Subgroup Estimation: Confirm that the propensity scores for subgroups were estimated separately, and discuss how the weights were subsequently combined with the original data.
- Covariate Balance: Include a Love plot to visually represent covariate balance on the exposure both before and after weighting.
- Weighting Algorithm Statistics: Report the statistics for the weighting algorithms as provided by the WeightIt package, including any measures of balance or fit.
- Outcome Regression Model: Clearly report the type of regression model used to estimate outcome model coefficients (e.g., linear regression, Poisson, binomial), and mention if the exposure was interacted with the baseline covariates. Do not report model coefficients as these have no interpretation.
- Subgroup Interaction: Address whether the subgroup was included separately as an interaction in the outcome model, and if the model successfully converged.
- Model Coefficients: Note that the model coefficients should not be interpreted, as they are not meaningful in this context.
- Confidence Intervals and Standard Errors: Describe the methods used to derive confidence intervals and standard errors, noting the use of the ‘clarify’ package in R for simulation based inference.
Example of how to report a doubly robust method in your report
The Doubly Robust Estimation method for Subgroup Analysis Estimator is a sophisticated tool combining features of both IPTW and G-computation methods, providing unbiased estimates if either the propensity score or outcome model is correctly specified. The process involves five main steps:
Step 1 involves the estimation of the propensity score, a measure of the conditional probability of exposure given the covariates and the subgroup indicator. This score is calculated using statistical models such as logistic regression, with the model choice depending on the nature of the data and exposure. Weights for each individual are then calculated using this propensity score. These weights depend on the exposure status and are computed differently for exposed and unexposed individuals. The estimation of propensity scores is performed separately within each subgroup stratum.
Step 2 focuses on fitting a weighted outcome model, making use of the previously calculated weights from the propensity scores. This model estimates the outcome conditional on exposure, covariates, and subgroup, integrating the weights into the estimation process. Unlike in propensity score model estimation, covariates are included as variables in the outcome model. This inclusion makes the method doubly robust - providing a consistent effect estimate if either the propensity score or the outcome model is correctly specified, thereby reducing the assumption of correct model specification.
Step 3 entails the simulation of potential outcomes for each individual in each subgroup. These hypothetical scenarios assume universal exposure to the intervention within each subgroup, regardless of actual exposure levels. The expectation of potential outcomes is calculated for each individual in each subgroup, using individual-specific weights. These scenarios are performed for both the current and alternative interventions.
Step 4 is the estimation of the average causal effect for each subgroup, achieved by comparing the computed expected values of potential outcomes under each intervention level. The difference represents the average causal effect of changing the exposure within each subgroup.
Step 5 involves comparing differences in causal effects across groups by calculating the differences in the estimated causal effects between different subgroups. Confidence intervals and standard errors for these calculations are determined using simulation-based inference methods (Greifer et al. 2023). This step allows for a comprehensive comparison of the impact of different interventions across various subgroups, while encorporating uncertainty.
Inference
Consider the following ideas about what to discuss in one’s findings: Consider the following ideas about what to discuss in one’s findings. The order of exposition might be different.
Summary of results: What did you find?
Interpretation of E-values: Interpret the E-values used for sensitivity analysis. State what they represent in terms of the robustness of the findings to potential unmeasured confounding.
Causal Effect Interpretation: What is the interest of the effect, if any, if an effect was observed? Interpret the average causal effect of changing the exposure level within each subgroup, and discuss its relevance to the research question.
Comparison of Subgroups: Discuss how differences in causal effect estimates between different subgroups, if observed, or if not observed, contribute to the overall findings of the study.
Uncertainty and Confidence Intervals: Consider the uncertainty around the estimated causal effects, and interpret the confidence intervals to understand the precision of the estimates.
Generalisability and Transportability: Reflect on the generalizability of the study results to other contexts or populations. Discuss any factors that might influence the transportability of the causal effects found in the study. (Again see lecture 9.)
Assumptions and Limitations: Reflect on the assumptions made during the study and identify any limitations in the methodology that could affect the interpretation of results. State that the implications of different intervention levels on potential outcomes are not analysed.
Theoretical Relevance: How are these findings relevant to existing theories.
Replication and Future Research: Consider how the study could be replicated or expanded upon in future research, and how the findings contribute to the existing body of knowledge in the field.
Real-world Implications: Discuss the real-world implications of the findings, and how they could be applied in policy, practice, or further research.
Appendix A: Details of Estimation Approaches
G-computation for Subgroup Analysis Estimator
Step 1: Estimate the outcome model. Fit a model for the outcome Y, conditional on the exposure A, the covariates L, and subgroup indicator G. This model can be a linear regression, logistic regression, or another statistical model. The goal is to capture the relationship between the outcome, exposure, confounders, and subgroups.
\hat{E}(Y|A,L,G) = f_Y(A,L,G; \theta_Y)
This equation represents the expected value of the outcome Y given the exposure A, covariates L, and subgroup G, as modelled by the function f_Y with parameters \theta_Y. This formulation allows for the prediction of the average outcome Y given certain values of A, L, and G.
Step 2: Simulate potential outcomes. For each individual in each subgroup, predict their potential outcome under the intervention A=a using the estimated outcome model:
\hat{E}(Y(a)|G=g) = \hat{E}[Y|A=a,L,G=g; \hat{\theta}_Y]
We also predict the potential outcome for everyone in each subgroup under the causal contrast, setting the intervention for everyone in that group to A=a':
\hat{E}(Y(a')|G=g) = \hat{E}[Y|A=a',L,G=g; \hat{\theta}_Y]
In these equations, Y represents the potential outcome, A is the intervention, L are the covariates, G=g represents the subgroup, and \theta_Y are the parameters of the outcome model.
Step 3: Calculate the estimated difference for each subgroup g:
\hat{\delta}_g = \hat{E}[Y(a)|G=g] - \hat{E}[Y(a')|G=g]
This difference \hat{\delta}_g represents the average causal effect of changing the exposure from level a' to level a within each subgroup g.
We use simulation-based inference methods to compute standard errors and confidence intervals (Greifer et al. 2023).
Step 4: Compare differences in causal effects by subgroups:
\hat{\gamma} = \hat{\delta}_g - \hat{\delta}_{g'}
where,
\hat{\gamma} = \overbrace{\big( \hat{E}[Y(a)|G=g] - \hat{E}[Y(a^{\prime})|G=g] \big)}^{\hat{\delta_g}} - \overbrace{\big(\hat{E}[Y(a^{\prime})|G=g^{\prime}]- \hat{E}[Y(a)|G=g^{\prime}]\big)}^{\hat{\delta_{g^{\prime}}}}
This difference \hat{\gamma} represents the difference in the average causal effects between the subgroups g and g'. It measures the difference in effect of the exposure A within subgroup G on the outcome Y.
We again use simulation-based inference methods to compute standard errors and confidence intervals (Greifer et al. 2023).
Inverse Probability of Treatment Weighting (IPTW) for Subgroup Analysis Estimator
Step 1: Estimate the propensity score. The propensity score e(L, G) is the conditional probability of the exposure A = 1, given the covariates L and subgroup indicator G. This can be modeled using logistic regression or other suitable methods, depending on the nature of the data and the exposure.
e = P(A = 1 | L, G) = f_A(L, G; \theta_A)
Here, f_A(L, G; \theta_A) is a function (statistical model) that estimates the probability of the exposure A = 1 given covariates L and subgroup G. Then, we calculate the weights for each individual, denoted as v, using the estimated propensity score:
v = \begin{cases} \frac{1}{e} & \text{if } A = 1 \\ \frac{1}{1-e} & \text{if } A = 0 \end{cases}
Step 2: Fit a weighted outcome model. Using the weights calculated from the estimated propensity scores, fit a model for the outcome Y, conditional on the exposure A and subgroup G. This can be represented as:
\hat{E}(Y|A, G; V) = f_Y(A, G ; \theta_Y, V)
In this model, f_Y is a function (such as a weighted regression model) with parameters θ_Y.
Step 3: Simulate potential outcomes. For each individual in each subgroup, simulate their potential outcome under the hypothetical scenario where everyone in the subgroup is exposed to the intervention A=a regardless of their actual exposure level:
\hat{E}(Y(a)|G=g) = \hat{E}[Y|A=a,G=g; \hat{\theta}_Y, v]
And also under the hypothetical scenario where everyone is exposed to intervention A=a':
\hat{E}(Y(a')|G=g) = \hat{E}[Y|A=a',G=g; \hat{\theta}_Y, v]
Step 4: Estimate the average causal effect for each subgroup as the difference in the predicted outcomes:
\hat{\delta}_g = \hat{E}[Y(a)|G=g] - \hat{E}[Y(a')|G=g]
The estimated difference \hat{\delta}_g represents the average causal effect within group g.
Step 5: Compare differences in causal effects by groups. Compute the differences in the estimated causal effects between different subgroups:
\hat{\gamma} = \hat{\delta}_g - \hat{\delta}_{g'}
where,
\hat{\gamma} = \overbrace{\big( \hat{E}[Y(a)|G=g] - \hat{E}[Y(a')|G=g] \big)}^{\hat{\delta_g}} - \overbrace{\big(\hat{E}[Y(a')|G=g']- \hat{E}[Y(a)|G=g']\big)}^{\hat{\delta_{g'}}}
This \hat{\gamma} represents the difference in the average causal effects between the subgroups g and g'.
We again use simulation-based inference methods to compute standard errors and confidence intervals (Greifer et al. 2023).
Doubly Robust Estimation for Subgroup Analysis Estimator
It appears that the Doubly Robust Estimation explanation for subgroup analysis is already clear and correct, covering all the necessary steps in the process. Nevertheless, there’s a slight confusion in step 4. The difference \delta_g is not defined within the document. I assume that you intended to write \hat{\delta}_g. Here’s the corrected version:
Doubly Robust Estimation for Subgroup Analysis Estimator
Doubly Robust Estimation is a powerful technique that combines the strengths of both the IPTW and G-computation methods. It uses both the propensity score model and the outcome model, which makes it doubly robust: it produces unbiased estimates if either one of the models is correctly specified.
Step 1 Estimate the propensity score. The propensity score e(L, G) is the conditional probability of the exposure A = 1, given the covariates L and subgroup indicator G. This can be modeled using logistic regression or other suitable methods, depending on the nature of the data and the exposure.
e = P(A = 1 | L, G) = f_A(L, G; \theta_A)
Here, f_A(L, G; \theta_A) is a function (statistical model) that estimates the probability of the exposure A = 1 given covariates L and subgroup G. Then, we calculate the weights for each individual, denoted as v, using the estimated propensity score:
v = \begin{cases} \frac{1}{e} & \text{if } A = 1 \\ \frac{1}{1-e} & \text{if } A = 0 \end{cases}
Step 2 Fit a weighted outcome model. Using the weights calculated from the estimated propensity scores, fit a model for the outcome Y, conditional on the exposure A, covariates L, and subgroup G.
\hat{E}(Y|A, L, G; V) = f_Y(A, L, G ; \theta_Y, V)
Step 3 For each individual in each subgroup, simulate their potential outcome under the hypothetical scenario where everyone in the subgroup is exposed to the intervention A=a regardless of their actual exposure level:
\hat{E}(Y(a)|G=g) = \hat{E}[Y|A=a,G=g; L,\hat{\theta}_Y, v]
And also under the hypothetical scenario where everyone in each subgroup is exposed to intervention A=a':
\hat{E}(Y(a')|G=g) = \hat{E}[Y|A=a',G=g; L; \hat{\theta}_Y, v]
Step 4 Estimate the average causal effect for each subgroup. Compute the estimated expected value of the potential outcomes under each intervention level for each subgroup:
\hat{\delta}_g = \hat{E}[Y(a)|G=g] - \hat{E}[Y(a')|G=g]
The estimated difference \hat{\delta}_g represents the average causal effect of changing the exposure from level a' to level a within each subgroup.
Step 5 Compare differences in causal effects by groups. Compute the differences in the estimated causal effects between different subgroups:
\hat{\gamma} = \hat{\delta}_g - \hat{\delta}_{g'}
where,
\hat{\gamma} = \overbrace{\big( \hat{E}[Y(a)|G=g] - \hat{E}[Y(a')|G=g] \big)}^{\hat{\delta_g}} - \overbrace{\big(\hat{E}[Y(a')|G=g']- \hat{E}[Y(a)|G=g']\big)}^{\hat{\delta_{g'}}}
We again use simulation-based inference methods to compute standard errors and confidence intervals (Greifer et al. 2023).
Appendix B: G-computation for Subgroup Analysis Estimator with Non-Additive Effects
Step 1: Estimate the outcome model. Fit a model for the outcome Y, conditional on the exposure A, the covariates L, subgroup indicator G, and interactions between A and G. This model can be a linear regression, logistic regression, or another statistical model. The goal is to capture the relationship between the outcome, exposure, confounders, subgroups, and their interactions.
\hat{E}(Y|A,L,G,AG) = f_Y(A,L,G,AG; \theta_Y)
This equation represents the expected value of the outcome Y given the exposure A, covariates L, subgroup G, and interaction term AG, as modeled by the function f_Y with parameters \theta_Y.
Step 2: Simulate potential outcomes. For each individual in each subgroup, predict their potential outcome under the intervention A=a using the estimated outcome model:
\hat{E}(Y(a)|G=g) = \hat{E}[Y|A=a,L,G=g,AG=ag; \hat{\theta}_Y]
We also predict the potential outcome for everyone in each subgroup under the causal contrast, setting the intervention for everyone in that group to A=a':
\hat{E}(Y(a')|G=g) = \hat{E}[Y|A=a',L,G=g,AG=a'g; \hat{\theta}_Y]
Step 3: Calculate the estimated difference for each subgroup g:
\hat{\delta}_g = \hat{E}[Y(a)|G=g] - \hat{E}[Y(a')|G=g]
Step 4: Compare differences in causal effects by subgroups:
\hat{\gamma} = \hat{\delta}_g - \hat{\delta}_{g'}
where,
\hat{\gamma} = \overbrace{\big( \hat{E}[Y(a)|G=g] - \hat{E}[Y(a^{\prime})|G=g] \big)}^{\hat{\delta_g}} - \overbrace{\big(\hat{E}[Y(a^{\prime})|G=g^{\prime}]- \hat{E}[Y(a)|G=g^{\prime}]\big)}^{\hat{\delta_{g^{\prime}}}}
This difference \hat{\gamma} represents the difference in the average causal effects between the subgroups g and g', taking into account the interaction effect of the exposure A and the subgroup G on the outcome Y.
Note that the interaction term AG (or ag and a'g in the potential outcomes) stands for the interaction between the exposure level and the subgroup. This term is necessary to accommodate the non-additive effects in the model. As before, we must ensure that potential confounders L are sufficient to control for confounding.
Appendix C: Doubly Robust Estimation for Subgroup Analysis Estimator with Interaction
Again, Doubly Robust Estimation combines the strengths of both the IPTW and G-computation methods. It uses both the propensity score model and the outcome model, which makes it doubly robust: it produces unbiased estimates if either one of the models is correctly specified.
Step 1 Estimate the propensity score. The propensity score e(L, G) is the conditional probability of the exposure A = 1, given the covariates L and subgroup indicator G. This can be modeled using logistic regression or other suitable methods, depending on the nature of the data and the exposure.
e = P(A = 1 | L, G) = f_A(L, G; \theta_A)
Here, f_A(L, G; \theta_A) is a function (statistical model) that estimates the probability of the exposure A = 1 given covariates L and subgroup G. Then, we calculate the weights for each individual, denoted as v, using the estimated propensity score:
v = \begin{cases} \frac{1}{e} & \text{if } A = 1 \\ \frac{1}{1-e} & \text{if } A = 0 \end{cases}
Step 2 Fit a weighted outcome model. Using the weights calculated from the estimated propensity scores, fit a model for the outcome Y, conditional on the exposure A, covariates L, subgroup G and the interaction between A and G.
\hat{E}(Y|A, L, G, AG; V) = f_Y(A, L, G, AG ; \theta_Y, V)
Step 3 For each individual in each subgroup, simulate their potential outcome under the hypothetical scenario where everyone in the subgroup is exposed to the intervention A=a regardless of their actual exposure level:
\hat{E}(Y(a)|G=g) = \hat{E}[Y|A=a,G=g, AG=ag; L,\hat{\theta}_Y, v]
And also under the hypothetical scenario where everyone in each subgroup is exposed to intervention A=a':
\hat{E}(Y(a')|G=g) = \hat{E}[Y|A=a',G=g, AG=a'g; L; \hat{\theta}_Y, v]
Step 4 Estimate the average causal effect for each subgroup. Compute the estimated expected value of the potential outcomes under each intervention level for each subgroup:
\hat{\delta}_g = \hat{E}[Y(a)|G=g] - \hat{E}[Y(a')|G=g]
The estimated difference \hat{\delta}_g represents the average causal effect of changing the exposure from level a' to level a within each subgroup.
Step 5 Compare differences in causal effects by groups. Compute the differences in the estimated causal effects between different subgroups:
\hat{\gamma} = \hat{\delta}_g - \hat{\delta}_{g'}
where,
\hat{\gamma} = \overbrace{\big( \hat{E}[Y(a)|G=g] - \hat{E}[Y(a')|G=g] \big)}^{\hat{\delta_g}} - \overbrace{\big(\hat{E}[Y(a')|G=g']- \hat{E}[Y(a)|G=g']\big)}^{\hat{\delta_{g'}}}
We again use simulation-based inference methods to compute standard errors and confidence intervals (Greifer et al. 2023).
Appendix D: Marginal Structural Models for Estimating Population Average Treatment Effect with Interaction (Doubly Robust)
Sometimes we will only wish to estimate a marginal effect. In that case.
Step 1 Estimate the propensity score. The propensity score e(L) is the conditional probability of the exposure A = 1, given the covariates L which contains the subgroup G. This can be modelled using logistic regression or other functions as described in Greifer et al. (2023)
e = P(A = 1 | L) = f_A(L; \theta_A)
Here, f_A(L; \theta_A) is a function (a statistical model) that estimates the probability of the exposure A = 1 given covariates L. Then, we calculate the weights for each individual, denoted as v, using the estimated propensity score:
v = \begin{cases} \frac{1}{e} & \text{if } A = 1 \\ \frac{1}{1-e} & \text{if } A = 0 \end{cases}
Step 2 Fit a weighted outcome model. Using the weights calculated from the estimated propensity scores, fit a model for the outcome Y, conditional on the exposure A and covariates L.
\hat{E}(Y|A, L; V) = f_Y(A, L; \theta_Y, V)
This model should include terms for both the main effects of A and L and their interaction AL.
Step 3 For the entire population, simulate the potential outcome under the hypothetical scenario where everyone is exposed to the intervention A=a regardless of their actual exposure level:
\hat{E}(Y(a)) = \hat{E}[Y|A=a; L,\hat{\theta}_Y, v]
And also under the hypothetical scenario where everyone is exposed to intervention A=a':
\hat{E}(Y(a')) = \hat{E}[Y|A=a'; L; \hat{\theta}_Y, v]
Step 4 Estimate the average causal effect for the entire population. Compute the estimated expected value of the potential outcomes under each intervention level for the entire population:
\hat{\delta} = \hat{E}[Y(a)] - \hat{E}[Y(a')]
The estimated difference \hat{\delta} represents the average causal effect of changing the exposure from level a' to level a in the entire population.
We again use simulation-based inference methods to compute standard errors and confidence intervals (Greifer et al. 2023).
References
Danaei, Goodarz, Mohammad Tavakkoli, and Miguel A. Hernán. 2012. “Bias in observational studies of prevalent users: lessons for comparative effectiveness research from a meta-analysis of statins.” American Journal of Epidemiology 175 (4): 250–62. https://doi.org/10.1093/aje/kwr301.
Greifer, Noah, Steven Worthington, Stefano Iacus, and Gary King. 2023. Clarify: Simulation-Based Inference for Regression Models. https://iqss.github.io/clarify/.
VanderWeele, Tyler J, Maya B Mathur, and Ying Chen. 2020. “Outcome-Wide Longitudinal Designs for Causal Inference: A New Template for Empirical Studies.” Statistical Science 35 (3): 437466.
Footnotes
A and G on Y might not be additive. We assume that the potential confounders L are sufficient to control for confounding. See Appendix↩︎
Reuse
MIT