---
title: "Causal Diagrams: The Structures of Interaction/Effect Modification, Measurement Bias, Selection Bias"
date: "2025-NOV-119"
bibliography: /Users/joseph/GIT/templates/bib/references.bib
editor_options:
chunk_output_type: console
format:
html:
warnings: false
error: false
messages: false
code-overflow: scroll
highlight-style: dracula
code-tools:
source: true
toggle: false
code-fold: false
html-math-method: katex
reference-location: margin
citation-location: margin
cap-location: margin
code-block-border-left: true
---
```{r}
#| echo: false
#| warning: false
# WARNING: COMMENT THIS OUT. JB DOES THIS FOR WORKING WITHOUT WIFI
#source("/Users/joseph/GIT/templates/functions/libs2.R")
# WARNING: COMMENT THIS OUT. JB DOES THIS FOR WORKING WITHOUT WIFI
#source("/Users/joseph/GIT/templates/functions/funs.R")
# ALERT: UNCOMMENT THIS AND DOWNLOAD THE FUNCTIONS FROM JB's GITHUB
# source(
# "https://raw.githubusercontent.com/go-bayes/templates/main/functions/experimental_funs.R"
# )
# source(
# "https://raw.githubusercontent.com/go-bayes/templates/main/functions/experimental_funs.R"
# )
# for making graphs
library("tinytex")
library("extrafont")
loadfonts(device = "all")
```
::: {.callout-note}
**Required**
- [@bulbulia2023] [link](https://www.cambridge.org/core/journals/evolutionary-human-sciences/article/methods-in-causal-inference-part-1-causal-diagrams-and-confounding/E734F72109F1BE99836E268DF3AA0359)
- see [simplified reading](https://osf.io/preprints/psyarxiv/tbjx8_v1)
**Optional**
- [@hernan2024WHATIF] Chapter 6-9 [link](https://www.dropbox.com/scl/fi/9hy6xw1g1o4yz94ip8cvd/hernanrobins_WhatIf_2jan24.pdf?rlkey=8eaw6lqhmes7ddepuriwk5xk9&dl=0)
- [@hernan2004STRUCTURAL] [link](https://www.dropbox.com/scl/fi/qni0y1lstntmdw410m2nh/Heran2004StructuralSelectionBias.pdf?rlkey=0ob86mmx7vscxqmn3ipg9m94f&dl=0)
- [@hernan2017SELECTIONWITHOUTCOLLIDER] [link](https://www.dropbox.com/scl/fi/zr3tk7ngsutjprqr18bbg/hernan-selection-without-colliders.pdf?rlkey=vfluyl3a7zksfphqepao04fix&dl=0)
- [@hernan2009MEASUREMENT] [link](https://www.dropbox.com/scl/fi/ip8nil6uc5l0x9xw14mbr/hernan_cole_Measure_causal_diagrams.pdf?rlkey=wkj3ayen8xb6ncog46sps2g49&dl=0)
- [@vanderweele2012MEASUREMENT] [link](https://www.dropbox.com/scl/fi/wtqoibuyitdwm5nlpjuu7/vander_hernan_measurement_error_vanderweel.pdf?rlkey=e4znxaqdfzf2vg6sj4ui799bb&dl=0)
:::
::: {.callout-important}
## Key concepts:
- **effect (measure) modification**
- **undirected/uncorrelated measurement error bias**
- **undirected/correlated measurement error bias**
- **directed/uncorrelated measurement error bias**
- **directed/correlated measurement error bias**
- **selection bias and transportability**
:::
# Exploring Bias
## Load libraries
```{r}
#| echo: false
#| warning: false
# data-wrangling
if (!require(tidyverse, quietly = TRUE)) {
install.packages("tidyverse")
library(tidyverse)
}
# graphing
if (!require(ggplot2, quietly = TRUE)) {
install.packages("ggplot2")
library(ggplot2)
}
# automated causal diagrams
if (!require(ggdag, quietly = TRUE)) {
install.packages("ggdag")
library(ggdag)
}
if (!require(ggdag, quietly = TRUE)) {
install.packages("parameters")
library(parameters)
}
if (!require(see, quietly = TRUE)) {
install.packages("see")
library(see)
}
```
We can use the `ggdag` package to evaluate confounding .
### Omitted Variable Bias Causal Graph
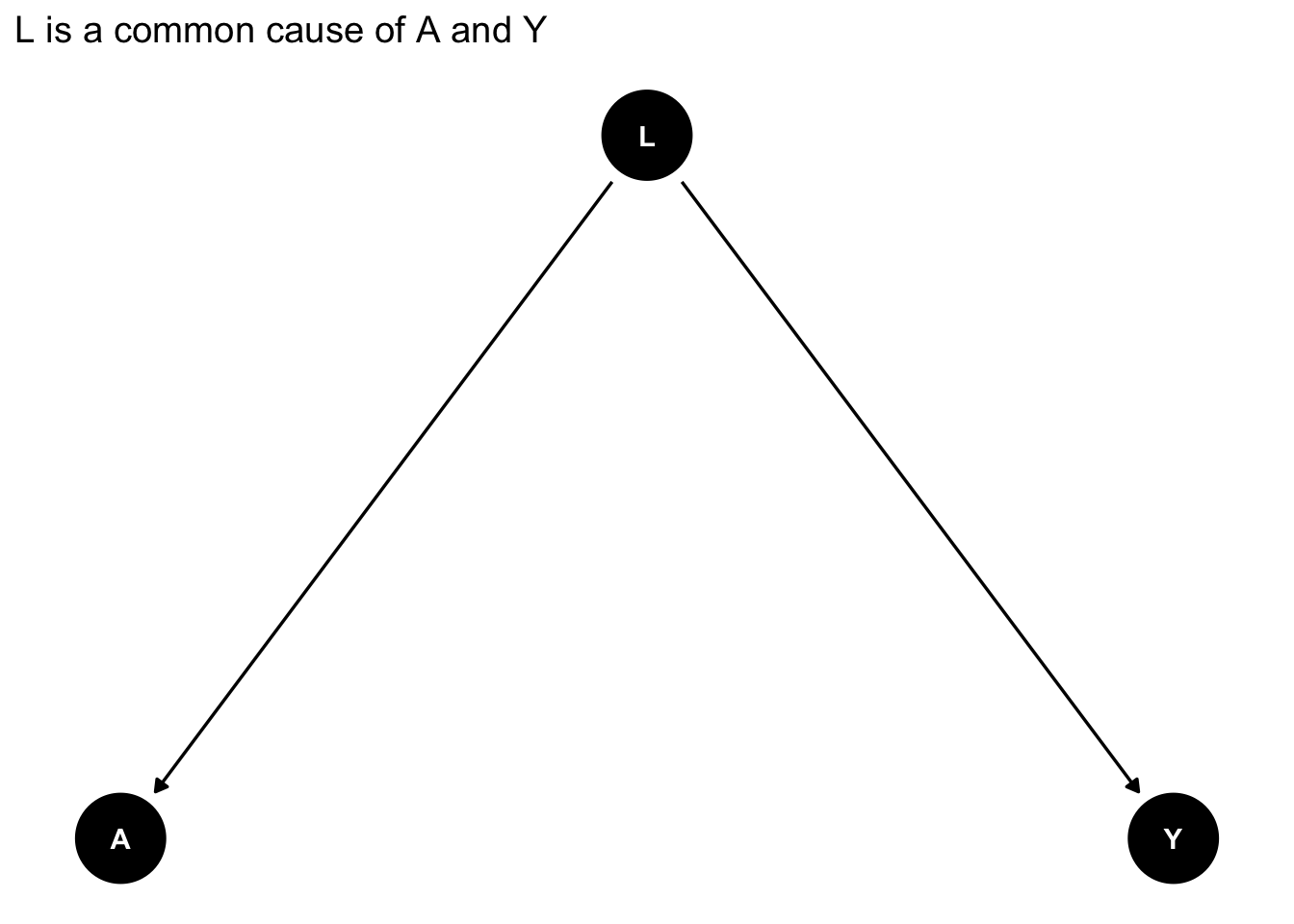
Let's use `ggdag` to identify confounding arising from omitting Z in our regression of X on Y.
First we write out the DAG as follows:
```{r}
# code for creating a DAG
graph_fork <- dagify(Y ~ L,
A ~ L,
exposure = "A",
outcome = "Y") |>
tidy_dagitty(layout = "tree")
# plot the DAG
graph_fork |>
ggdag() + theme_dag_blank() + labs(title = "L is a common cause of A and Y")
```
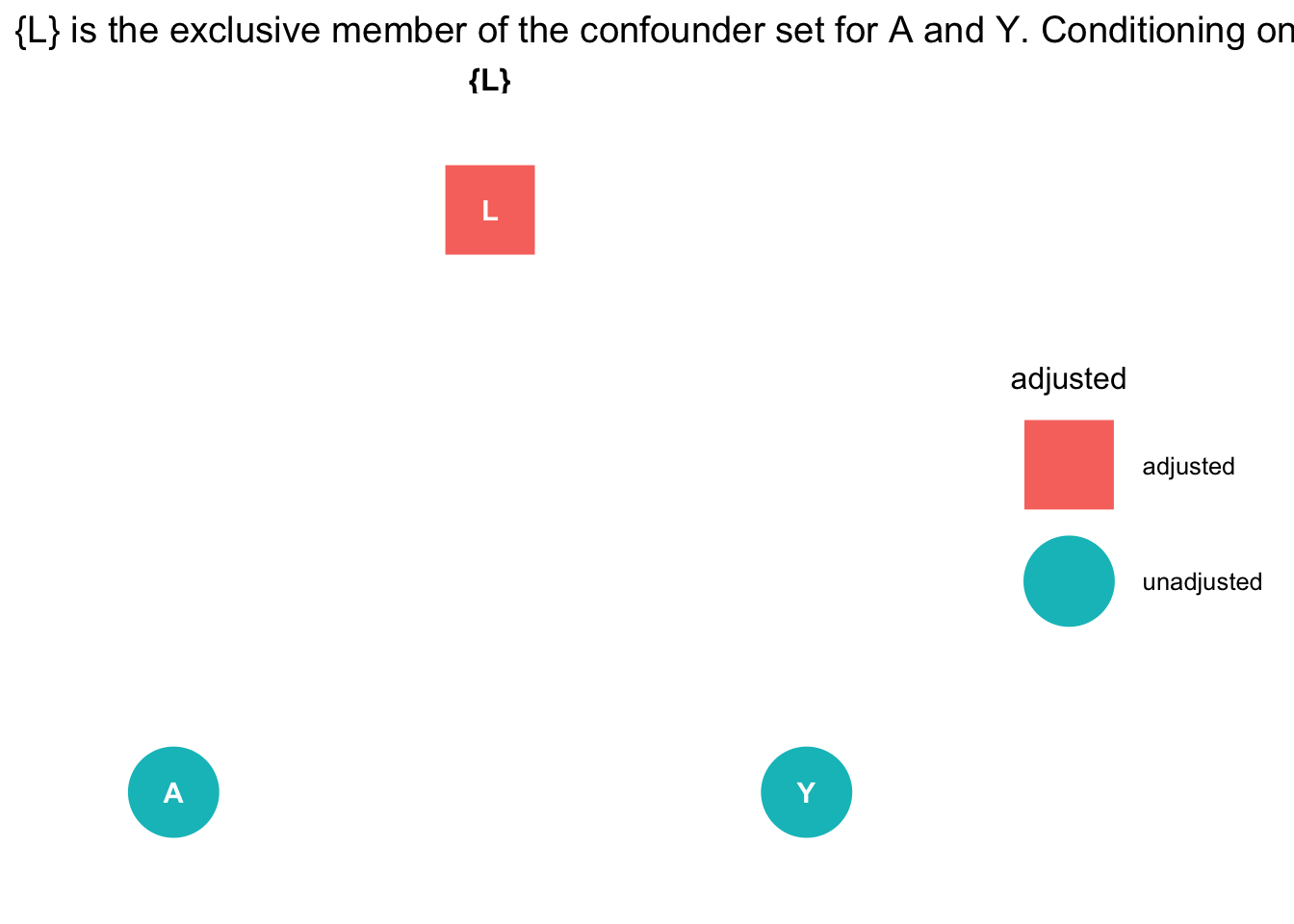
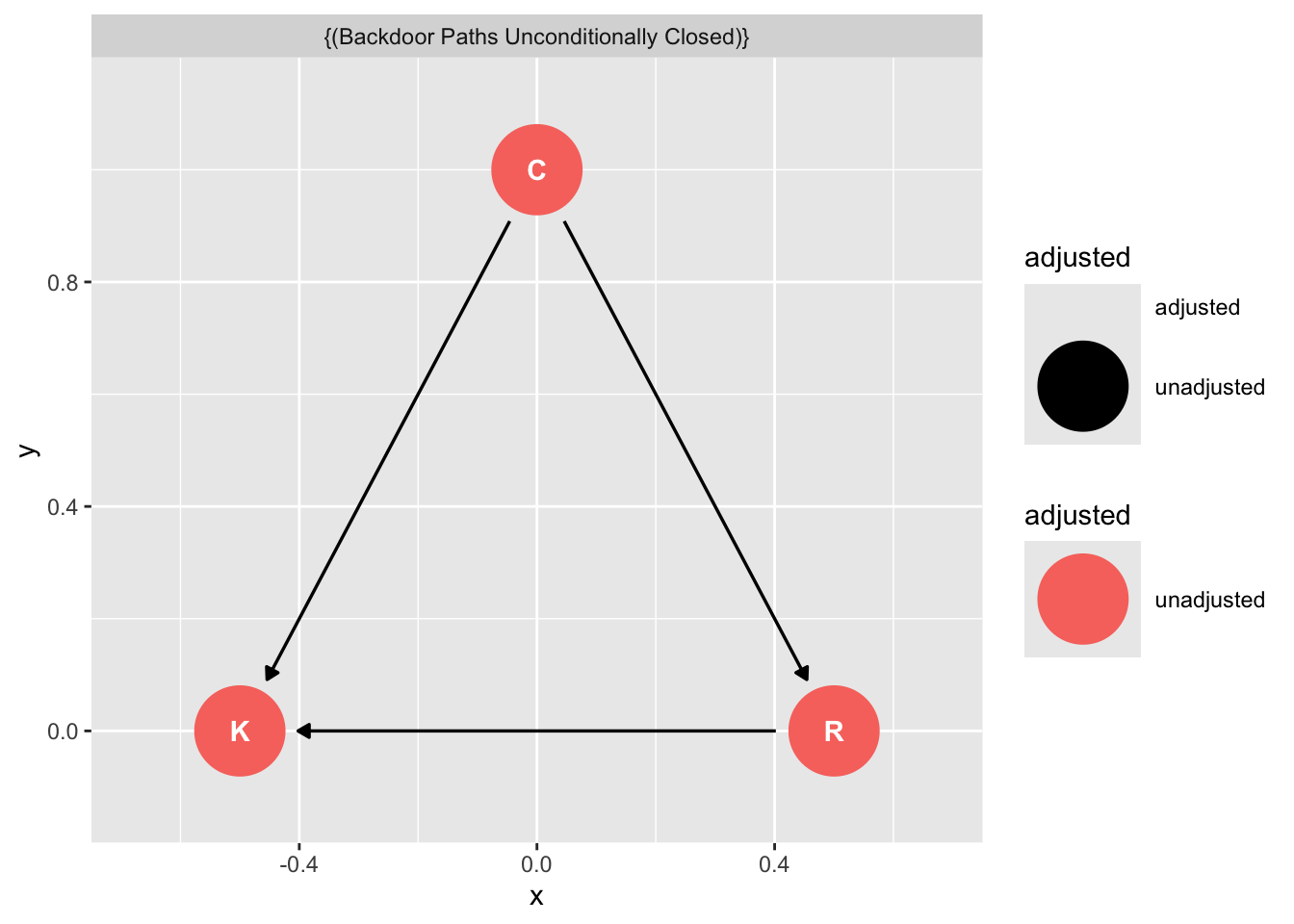
Next we ask `ggdag` which variables we need to include if we are to obtain an unbiased estimate of the outcome from the exposure:
```{r}
# use this code
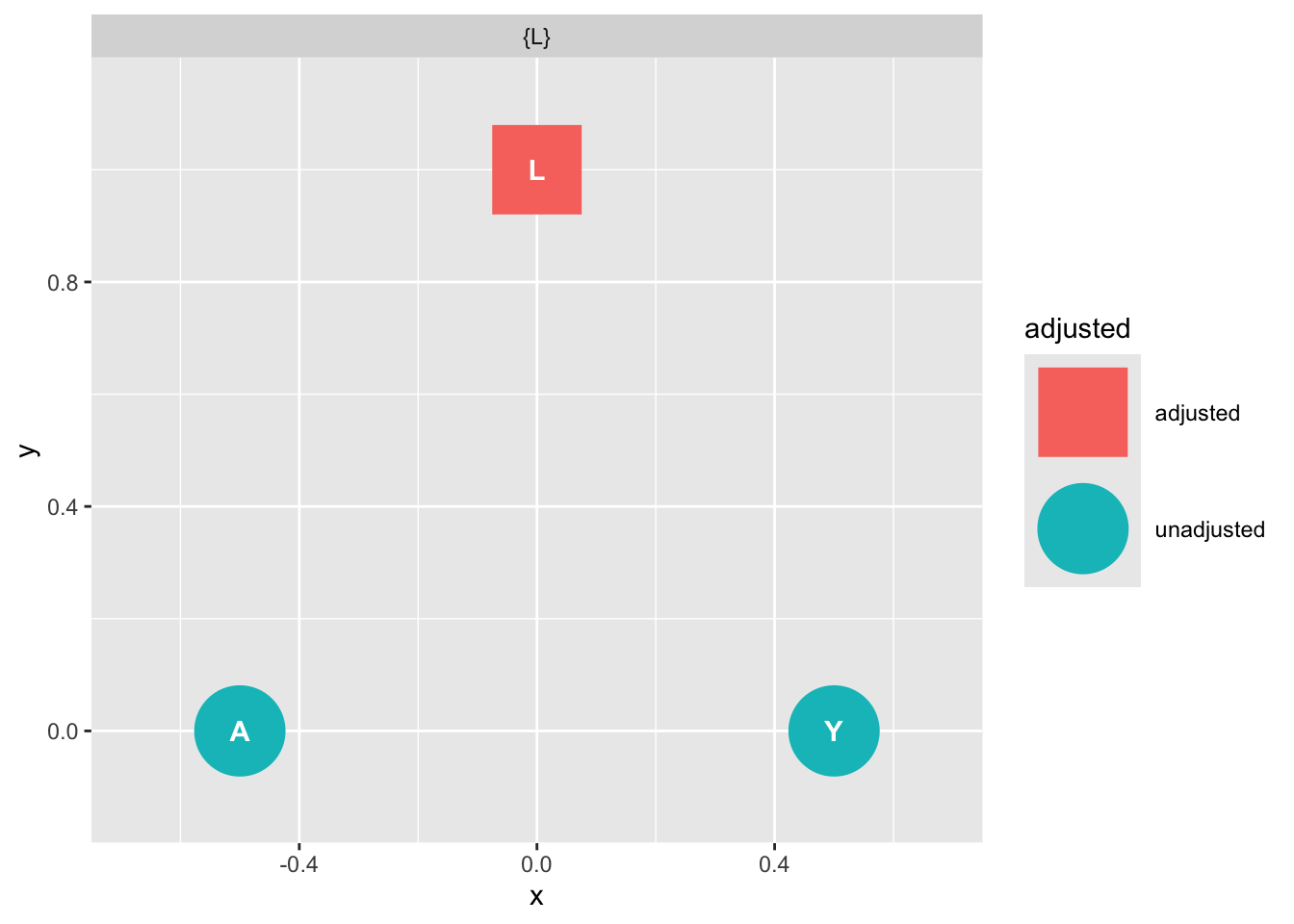
ggdag::ggdag_adjustment_set( graph_fork ) + theme_dag_blank() + labs(title = "{L} is the exclusive member of the confounder set for A and Y. Conditioning on L 'd-separates' A and Y ")
```
The causal graph tells us to obtain an unbiased estimate of A on Y we must condition on L.
And indeed, when we included the omitted variable L in our simulated dateset it breaks the association between X and Y:
```{r}
# set seed
set.seed(123)
# number of observations
N = 1000
# confounder
L = rnorm(N)
# A is caused by
A = rnorm(N, L)
# Y draws randomly from L but is not caused by A
Y = rnorm(N, L)
# note we did not need to make a data frame
# regress Y on A without control
fit_fork <- lm(Y ~ A)
# A is "significant
parameters::model_parameters(fit_fork)
# regress Y on A with control
fit_fork_controlled <- lm(Y ~ A + L)
# A and Y are no longer associated, conditioning worked.
parameters::model_parameters(fit_fork_controlled)
```
## Mediation and causation
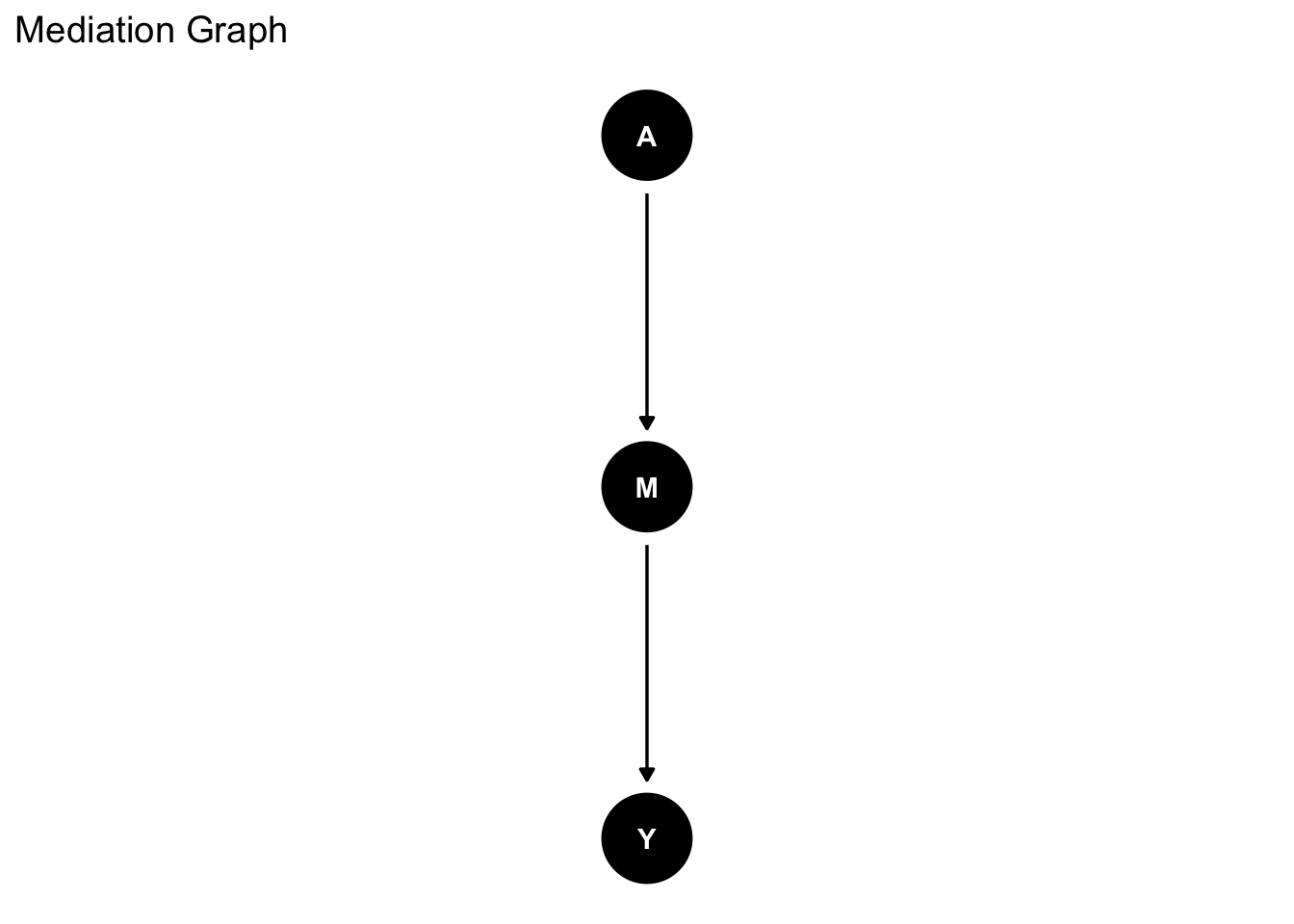
Suppose we were interested in the causal effect of X on Y. We have a direct effect of X on Y as well as an indirect effect of X on Y through M. We use `ggdag` to draw the DAG:
```{r}
graph_mediation <- dagify(Y ~ M,
M ~ A,
exposure = "A",
outcome = "Y") |>
ggdag::tidy_dagitty(layout = "tree")
graph_mediation |>
ggdag() +
theme_dag_blank() +
labs(title = "Mediation Graph")
```
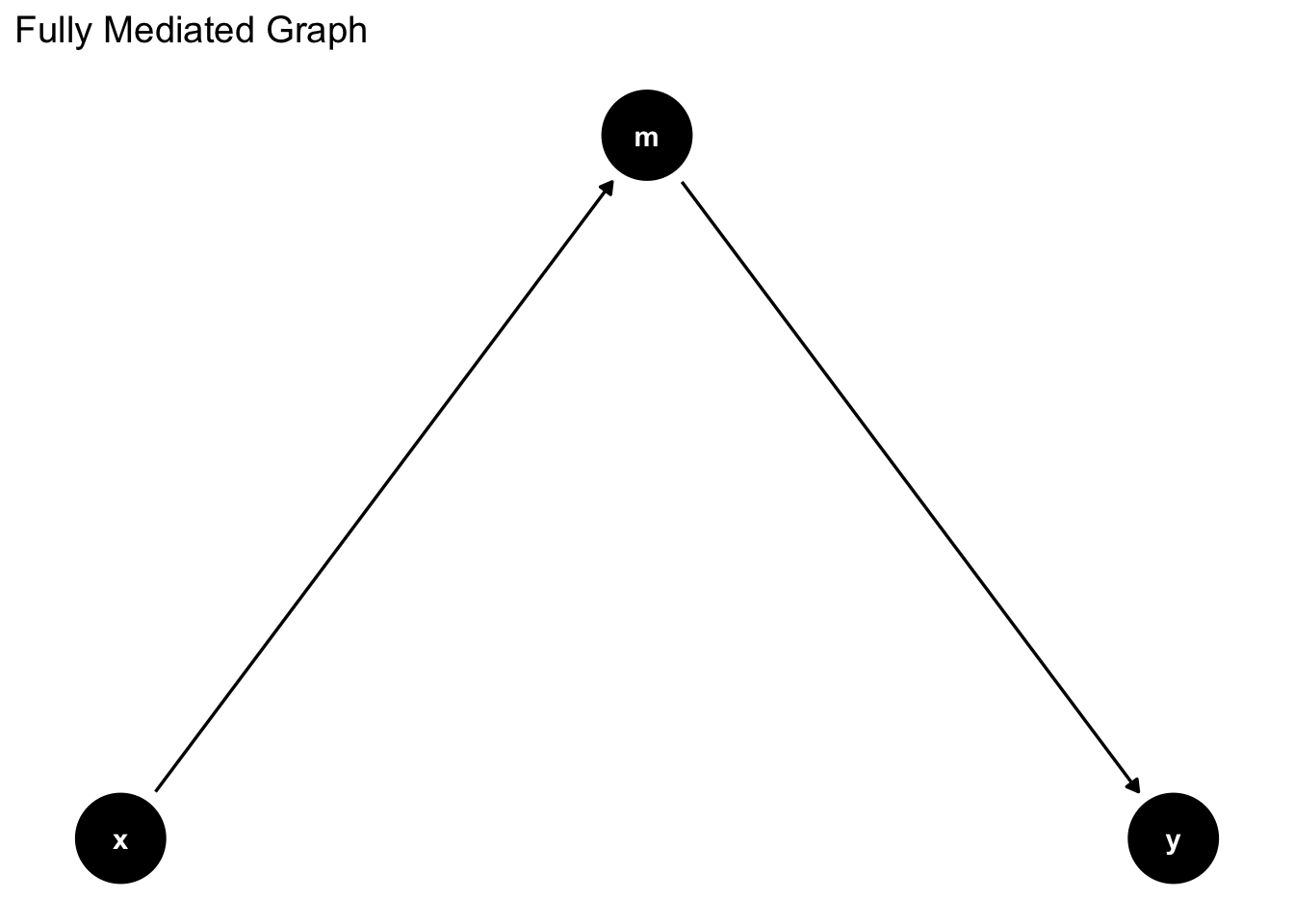
Here is another way
```{r}
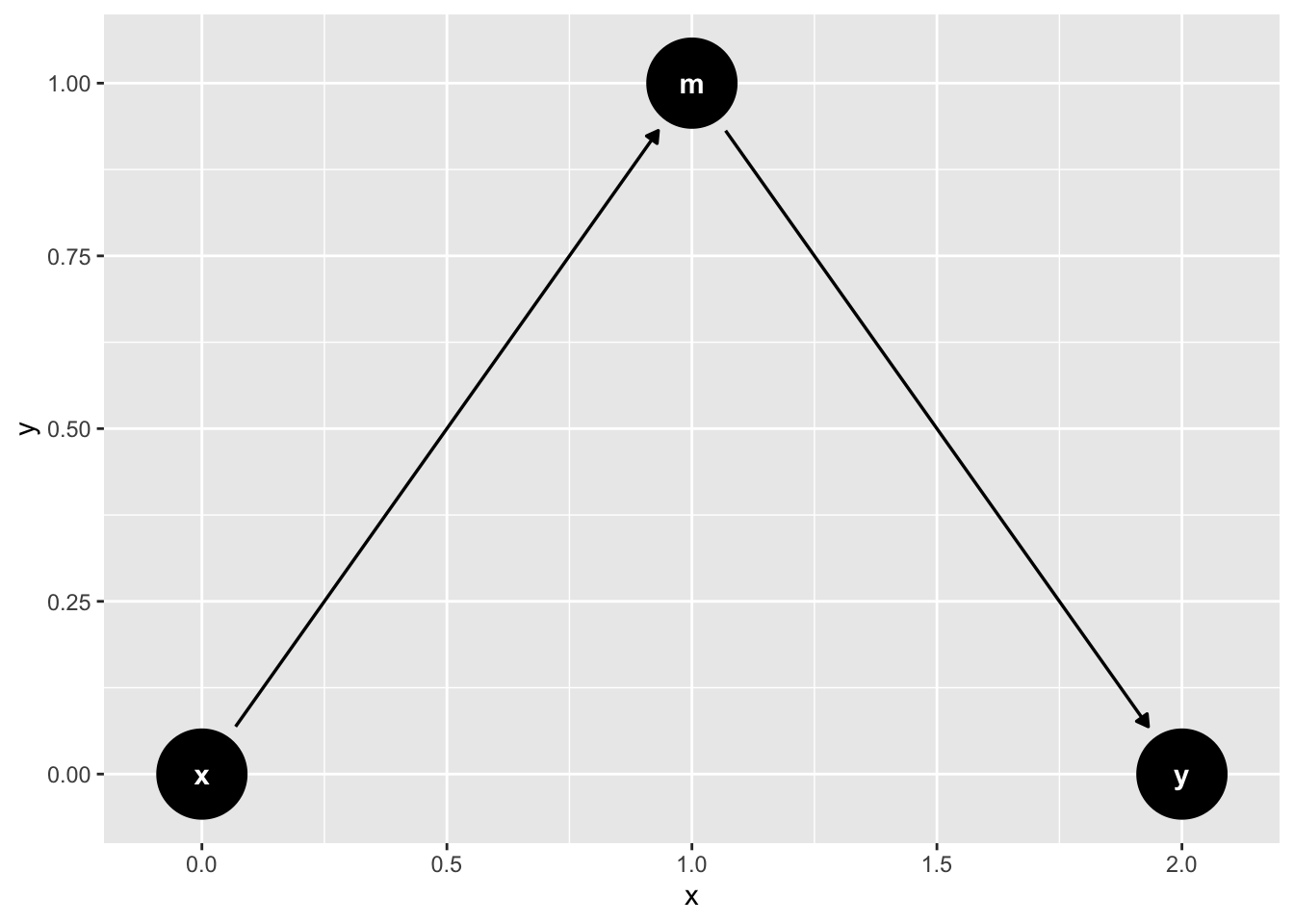
graph_mediation_full <- ggdag_mediation_triangle(x = "A",
y = "Y",
m = "M",
x_y_associated = FALSE)
graph_mediation_full + theme_dag_blank() +
labs(title = "Fully Mediated Graph")
```
What should we condition on if we are interested in the causal effect of changes in X on changes in Y?
We can pose the question to `ggdag`:
```{r}
# ask ggdag which variables to condition on:
ggdag::ggdag_adjustment_set(graph_fork)
```
'Backdoor Paths Unconditionally Closed' means that, assuming the DAG we have drawn is correct, we may obtain an unbiased estimate of X on Y without including additional variables.
Later we shall understand why this is the case.^[We shall see there is no "backdoor path" from X to Y that would bias our estimate, hence the estimate X->Y is an unbiased causal estimate -- again, conditional on our DAG.]
For now, we can enrich our language for causal inference by considering the concept of `d-connected` and `d-separated`:
Two variables are `d-connected` if information flows between them (condional on the graph), and they are `d-separated` if they are conditionally independent of each other.
```{r}
# use this code to examine d-connectedness
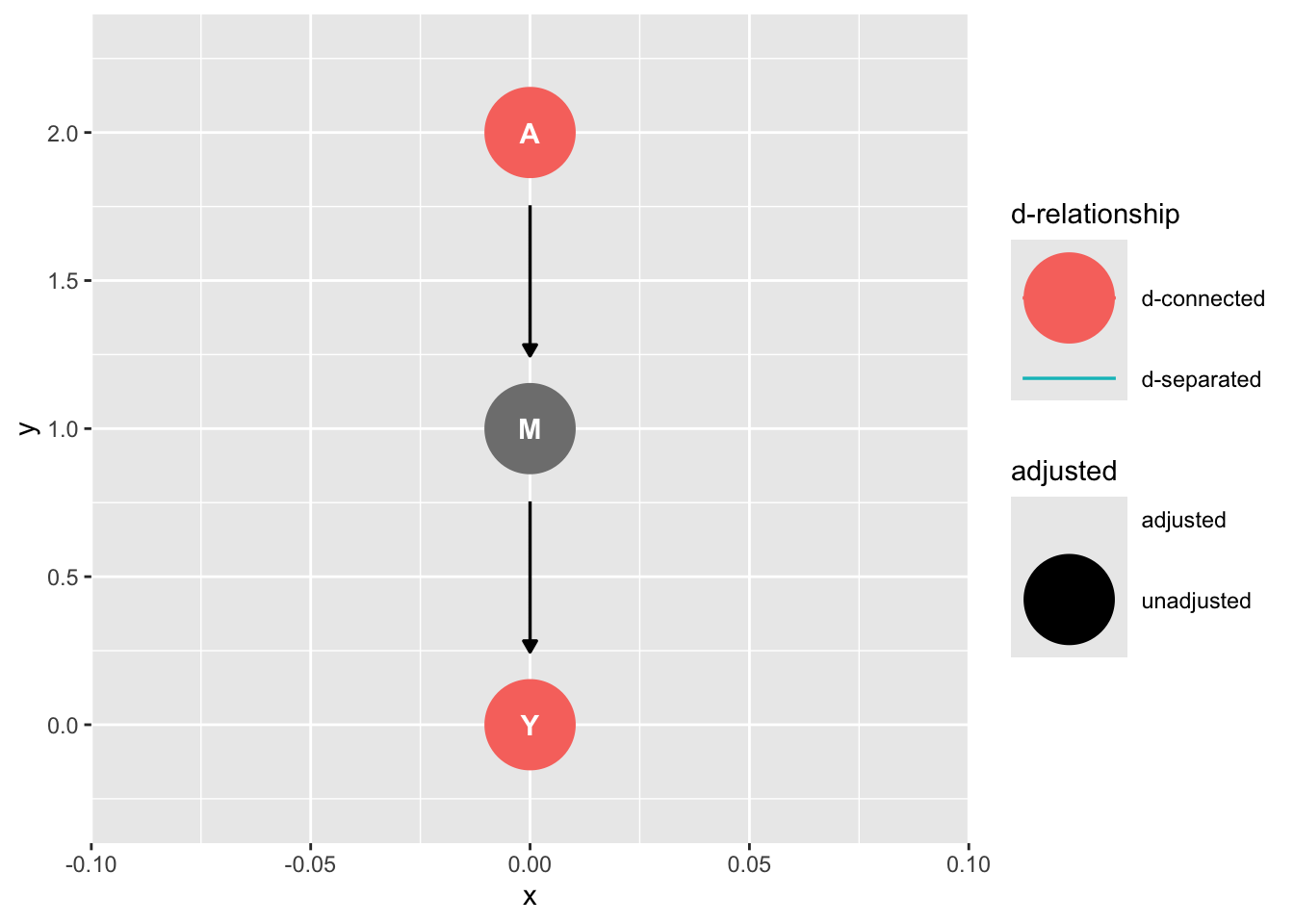
ggdag::ggdag_dconnected(graph_mediation)
```
In this case, d-connection is a good thing because we can estimate the causal effect of A on Y.
In other cases, d-connection will spoil the model. We have seen this for omitted variable bias. A and Y are d-separated conditional on L, and that's our motivation for including L. These concepts are tricky, but they get easier with practice.
To add some grit to our exploration of mediation lets simulate data that are consistent with our mediation DAG
```{r echo = TRUE, include = TRUE}
set.seed(123)
N <- 100
x <- rnorm(N)# sim x
m <- rnorm(N , x) # sim X -> M
y <- rnorm(N , x + m) # sim M -> Y
df <- data.frame(x, m, y)
df <- df |>
dplyr::mutate(x_s = scale(x),
m_s = scale(m))
```
First we ask, is X is related to Y?
```{r}
fit_mediation <- lm(y ~ x_s, data = df)
parameters::model_parameters(fit_mediation)
```
Yes.
Next we ask, is A related to Y conditional on M?
```{r}
fit_total_mediated_effect <- lm(y ~ x_s + m_s, data = df)
parameters::model_parameters(fit_total_mediated_effect) |> parameters::print_html()
```
Yes, but notice this is a different question. The effect of X is attenuated because M contributes to the causal effect of Y.
```{r}
fit_total_effect <- lm(y ~ x_s, data = df)
parameters::model_parameters(fit_total_effect) |> parameters::print_html()
```
## Pipe confounding (full mediation)
Suppose we are interested in the effect of x on y, in a scenario when m fully mediates the relationship of x on y.
```{r}
mediation_triangle(
x = NULL,
y = NULL,
m = NULL,
x_y_associated = FALSE
) |>
ggdag()
```
What variables do we need to include to obtain an unbiased estimate of X on Y?
Let's fill out this example out by imagining an experiment.
Suppose we want to know whether a ritual action condition (X) influences charity (Y). We have good reason to assume the effect of X on Y happens *entirely* through perceived social cohesion (M):
X$\to$M$\to$Z or
ritual $\to$ social cohesion $\to$ charity
Lets simulate some data
```{r}
set.seed(123)
# Participants
N <-100
# initial charitable giving
c0 <- rnorm(N ,10 ,2)
# assign treatments and simulate charitable giving and increase in social cohesion
ritual <- rep( 0:1 , each = N/2 )
cohesion <- ritual * rnorm(N,.5,.2)
# increase in charity
c1 <- c0 + ritual * cohesion
# dataframe
d <- data.frame( c0 = c0 ,
c1=c1 ,
ritual = ritual ,
cohesion = cohesion )
skimr::skim(d)
```
Does the ritual increase charity?
If we only include the ritual condition in the model, we find that ritual condition reliable predicts increases in charitable giving:
```{r}
parameters::model_parameters(
lm(c1 ~ c0 + ritual, data = d)
)
```
Does the ritual increase charity adjusting for levels of social cohesion?
```{r}
parameters::model_parameters(
lm(c1 ~ c0 + ritual + cohesion, data = d)
)
```
The answer is that the (direct) effect of ritual entirely drops out when we include both ritual and social cohesion. Why is this? The answer is that once our model knows `m` it does not obtain any new information by knowing `x`.
If we were interested in assessing x$\to$y but x were to effect y through m (i.e x$\to$m$\to$y) then conditioning on m would **block the path** from x$\to$y. Including m leads to **Pipe Confounding**.
In experiments we should never condition on a post-treatment variable.
## Masked relationships
Imagine two variables were to affect an outcome. Both are correlated with each other. One affects the outcome positively and the other affects the outcome negatively. How shall we investigate the causal role of the focal predictor?
Consider two correlated variables that jointly predict Political conservatism (C), religion (R). Imagine that one variable has a positive effect and the other has a negative effect on distress (K6).
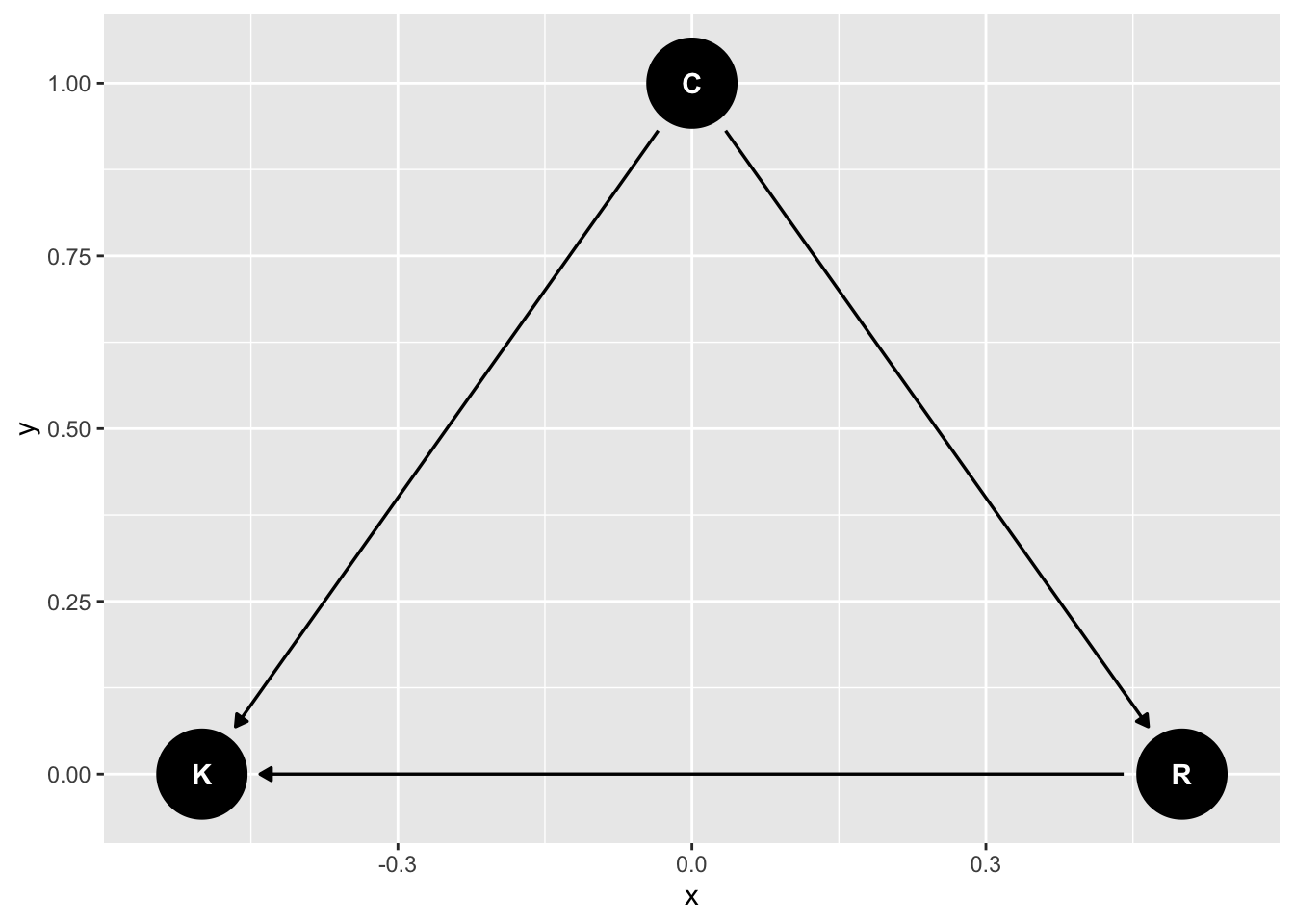
First consider this relationship, where conservatism causes religion
```{r}
library(ggdag)
dag_m1 <- dagify(K ~ C + R,
R ~ C,
exposure = "C",
outcome = "K") |>
tidy_dagitty(layout = "tree")
# graph
dag_m1|>
ggdag()
```
We can simulate the data:
```{r}
# C -> K <- R
# C -> R
set.seed(123)
n <- 100
C <- rnorm( n )
R <- rnorm( n , C )
K <- rnorm( n , R - C )
d_sim <- data.frame(K=K,R=R,C=C)
```
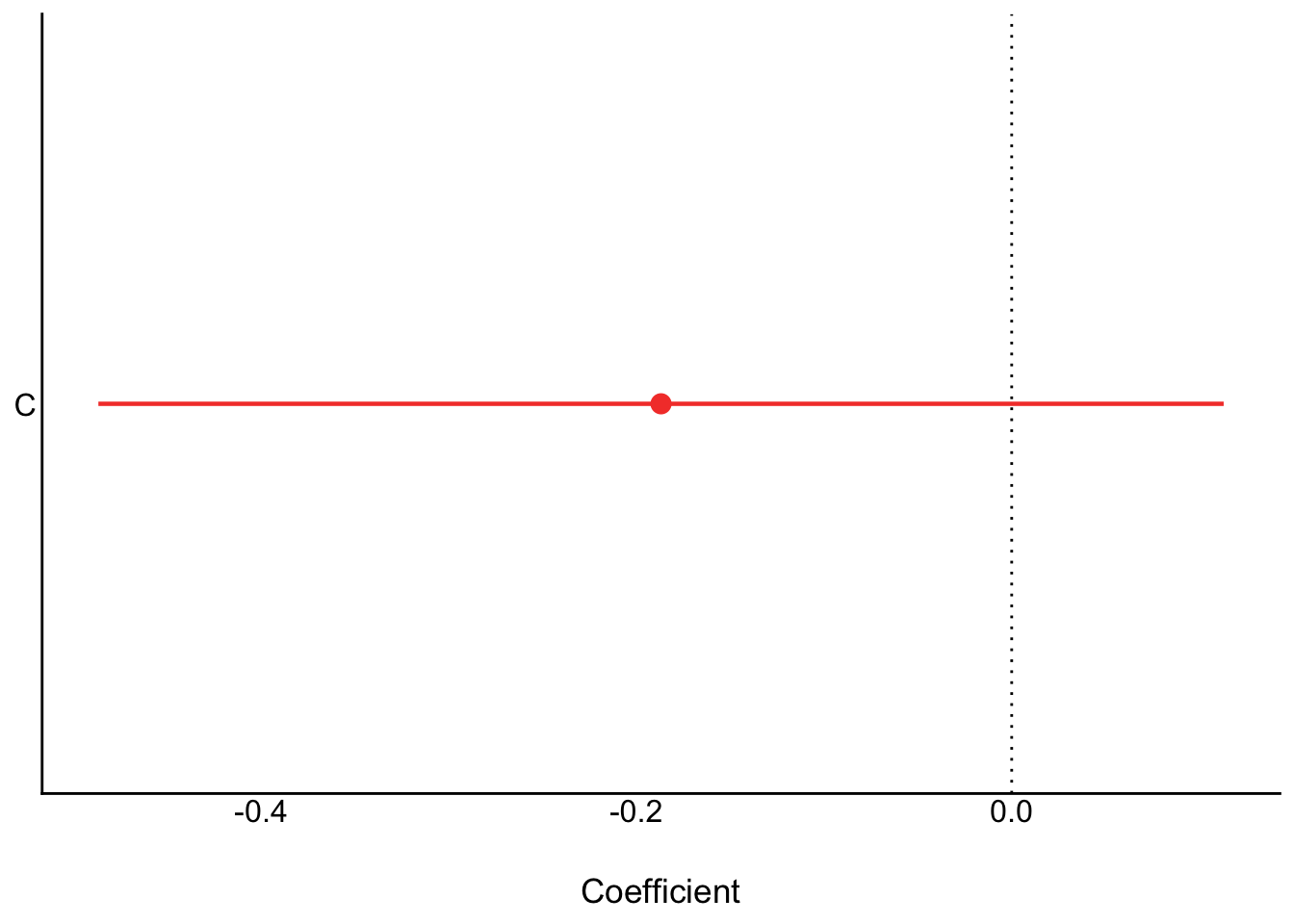
First we only condition on conservatism
```{r}
ms1 <- parameters::model_parameters(
lm(K ~ C, data = d_sim)
)
plot(ms1)
ms1
```
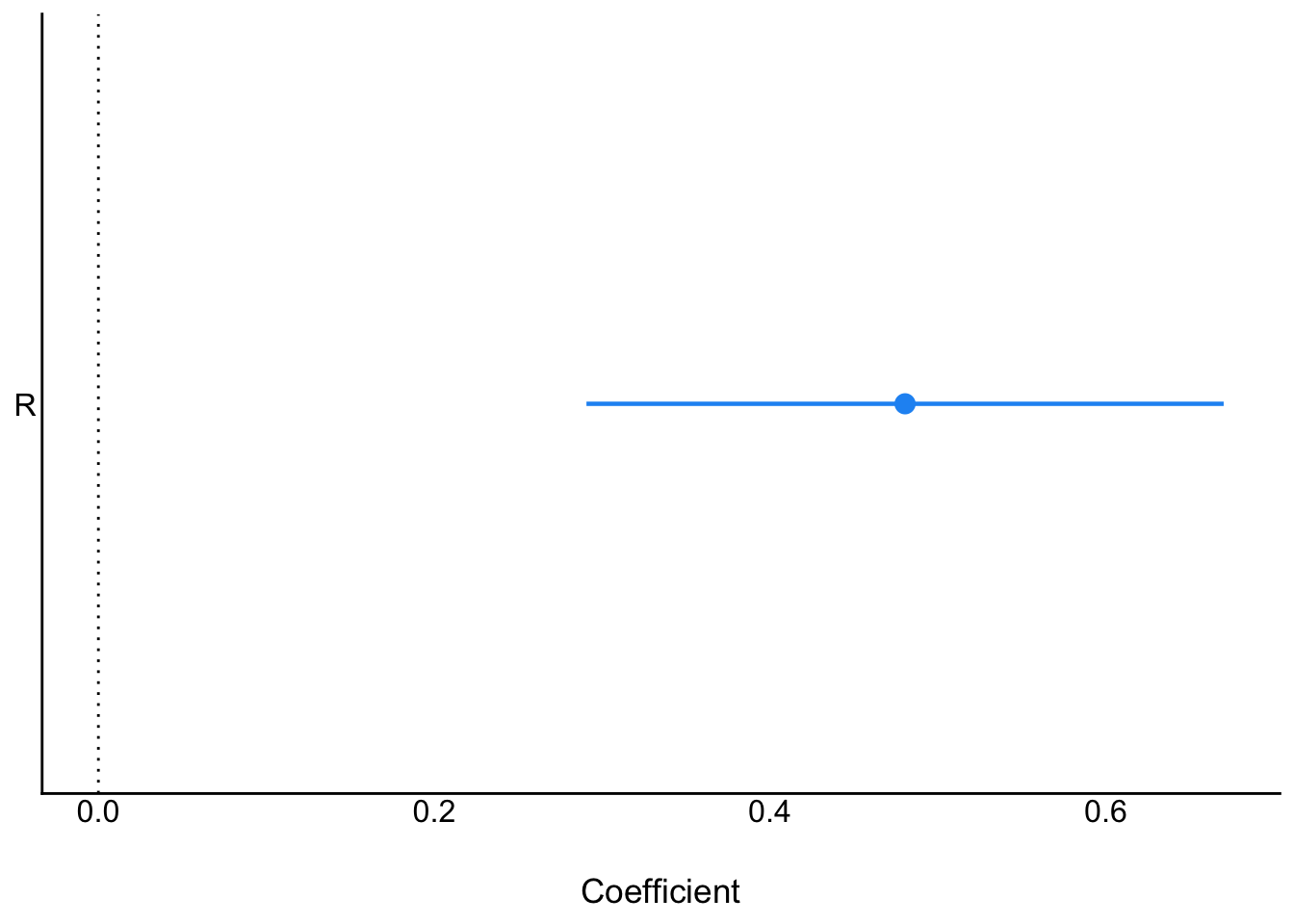
Next, only religion:
```{r}
ms2<- parameters::model_parameters(
lm(K ~ R, data = d_sim)
)
plot(ms2)
```
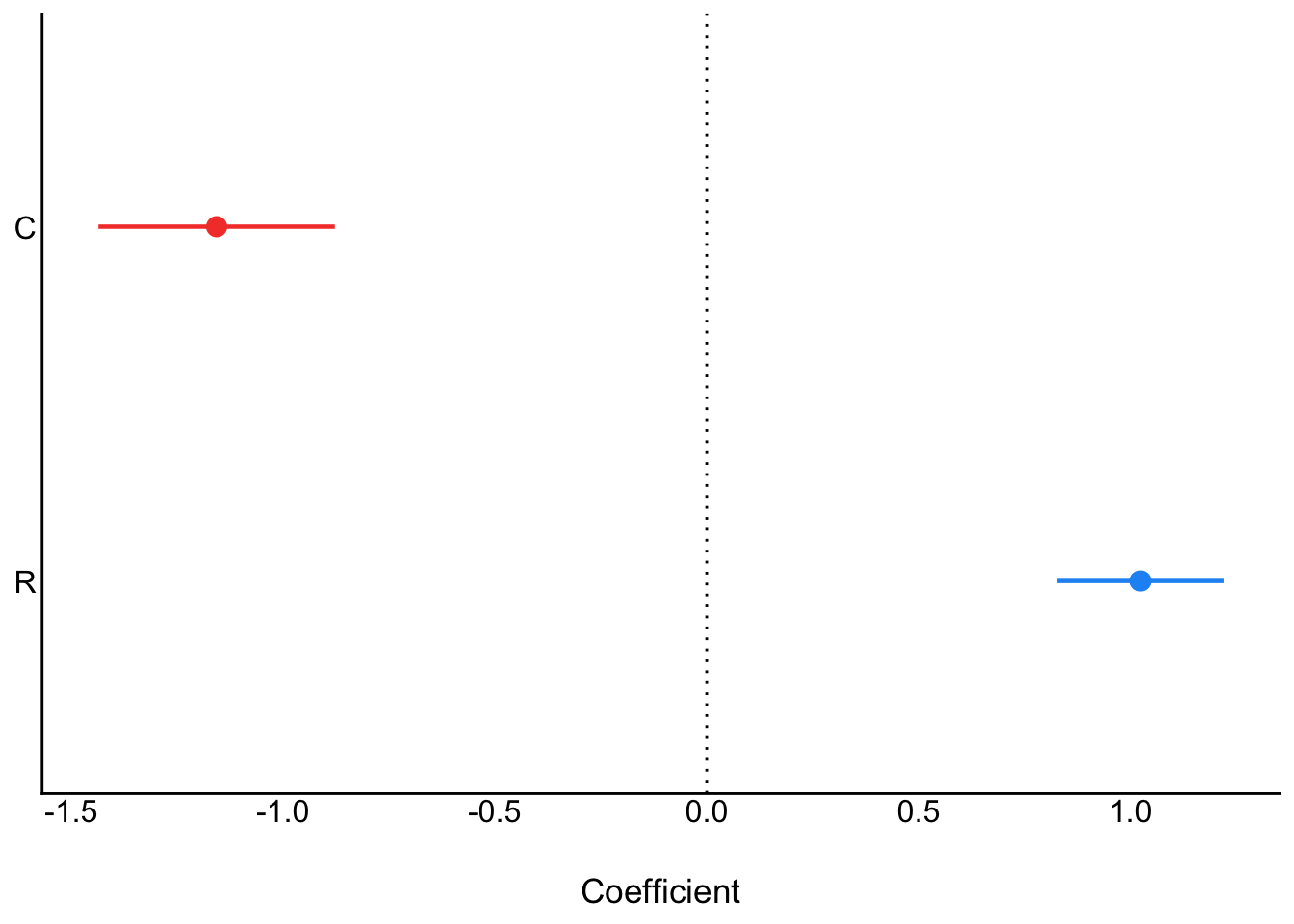
When we add both C and R, we see them "pop" in opposite directions, as is typical of masking:
```{r}
ms3<- parameters::model_parameters(
lm(K ~ C + R, data = d_sim)
)
plot(ms3)
```
Note that when you ask `ggdag` to assess how to obtain an unbiased estimate of C on K it will tell you you don't need to condition on R.
```{r}
dag_m1|>
ggdag_adjustment_set()
```
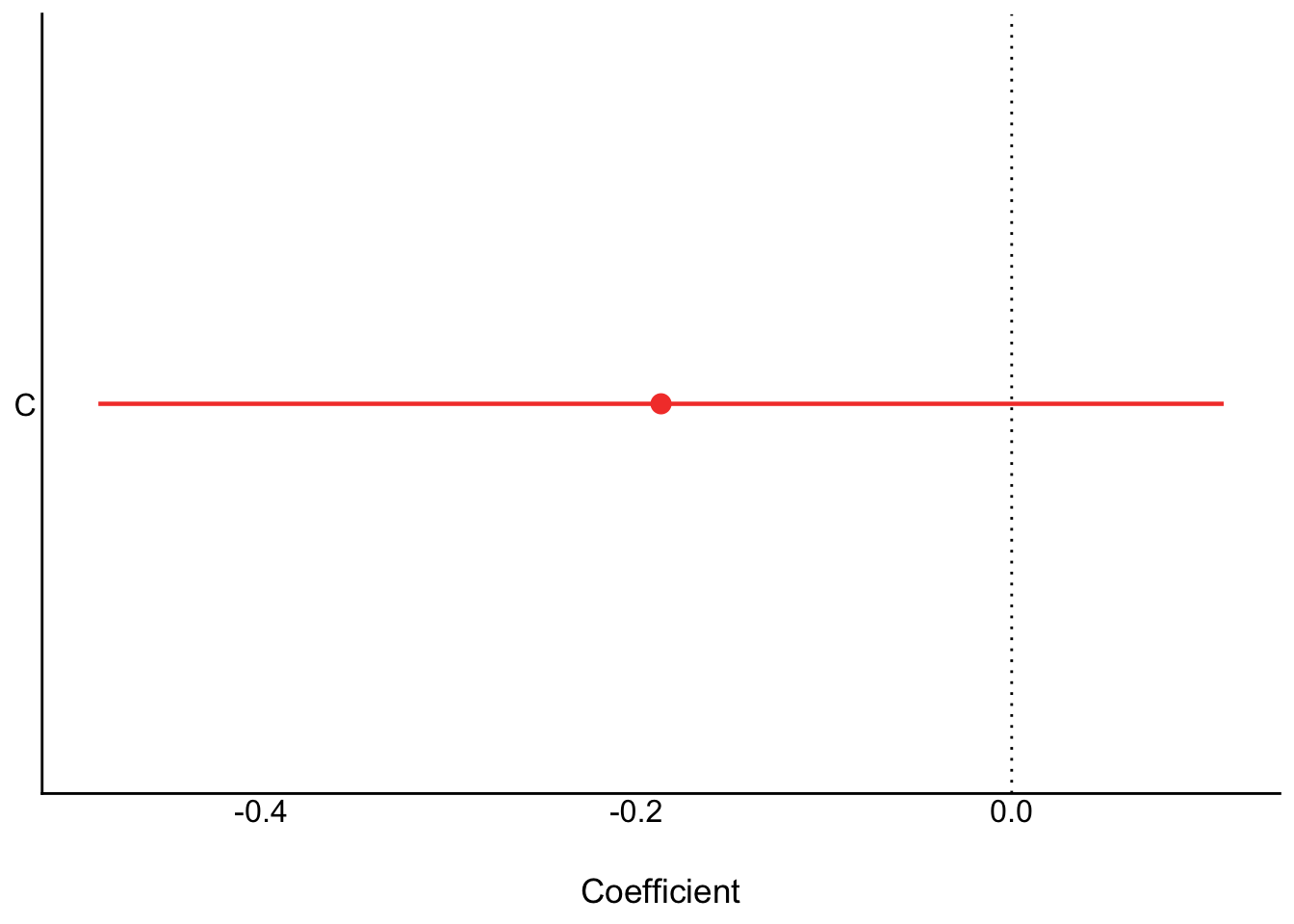
Yet recall when we just assessed the relationship of C on K we got this:
```{r}
plot(ms1)
```
Is the DAG wrong?
No. The fact that C$\to$R is positive and R$\to$K is negative means that if we were to increase C, we wouldn't reliably increase K. The total effect of C just isn't reliable
## Collider Confounding
The selection-distortion effect (Berkson's paradox)
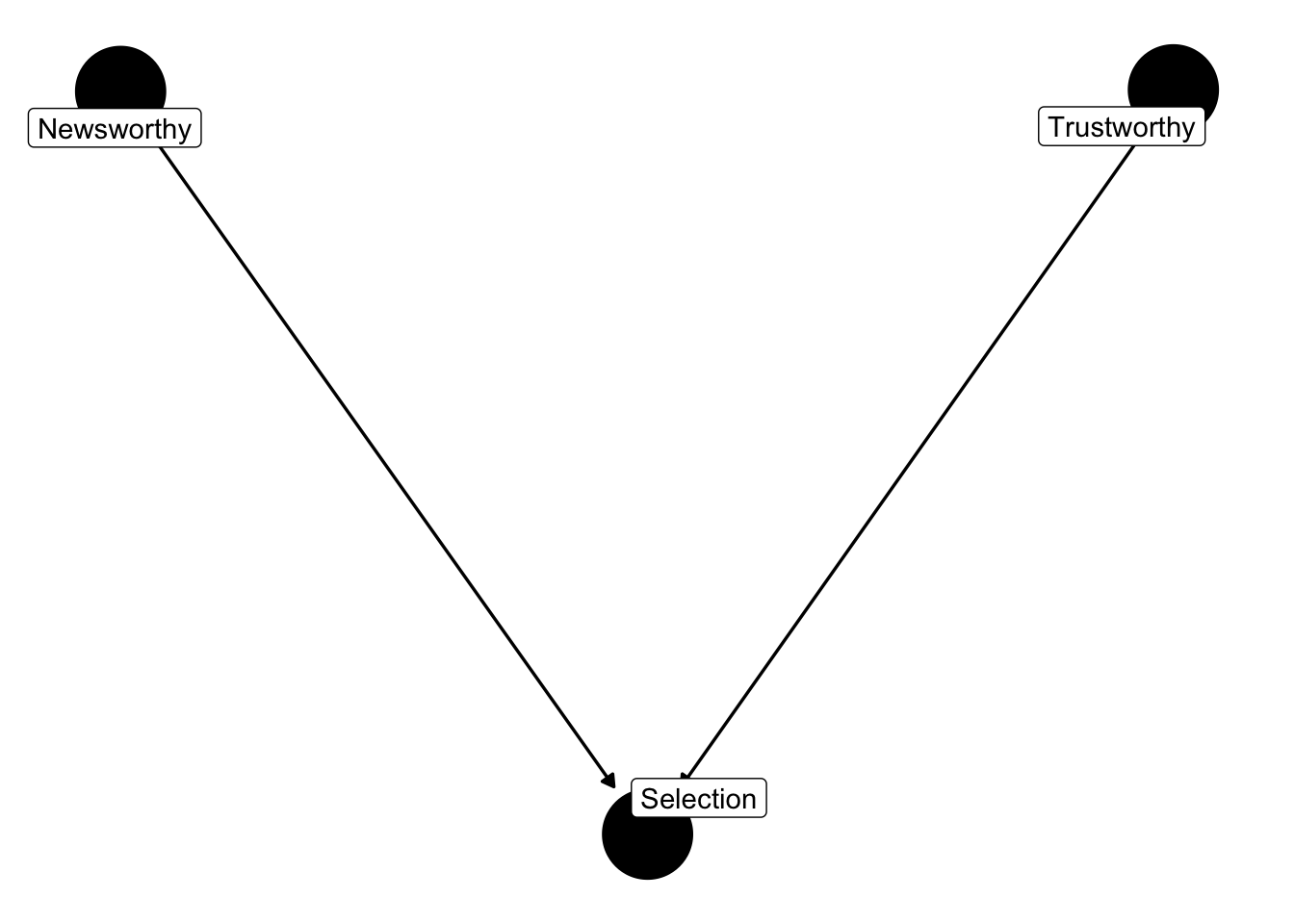
This example is from the book **Statistical Rethinking**. Imagine in science there is no relationship between the newsworthiness of science and its trustworthiness. Imagine further that selection committees make decisions on the basis of the both newsworthiness and the trustworthiness of scientific proposals.
This presents us with the following graph
```{r code_folding = TRUE}
dag_sd <- dagify(S ~ N,
S ~ T,
labels = c("S" = "Selection",
"N" = "Newsworthy",
"T" = "Trustworthy")) |>
tidy_dagitty(layout = "nicely")
# Graph
dag_sd |>
ggdag(text = FALSE, use_labels = "label") + theme_dag_blank()
```
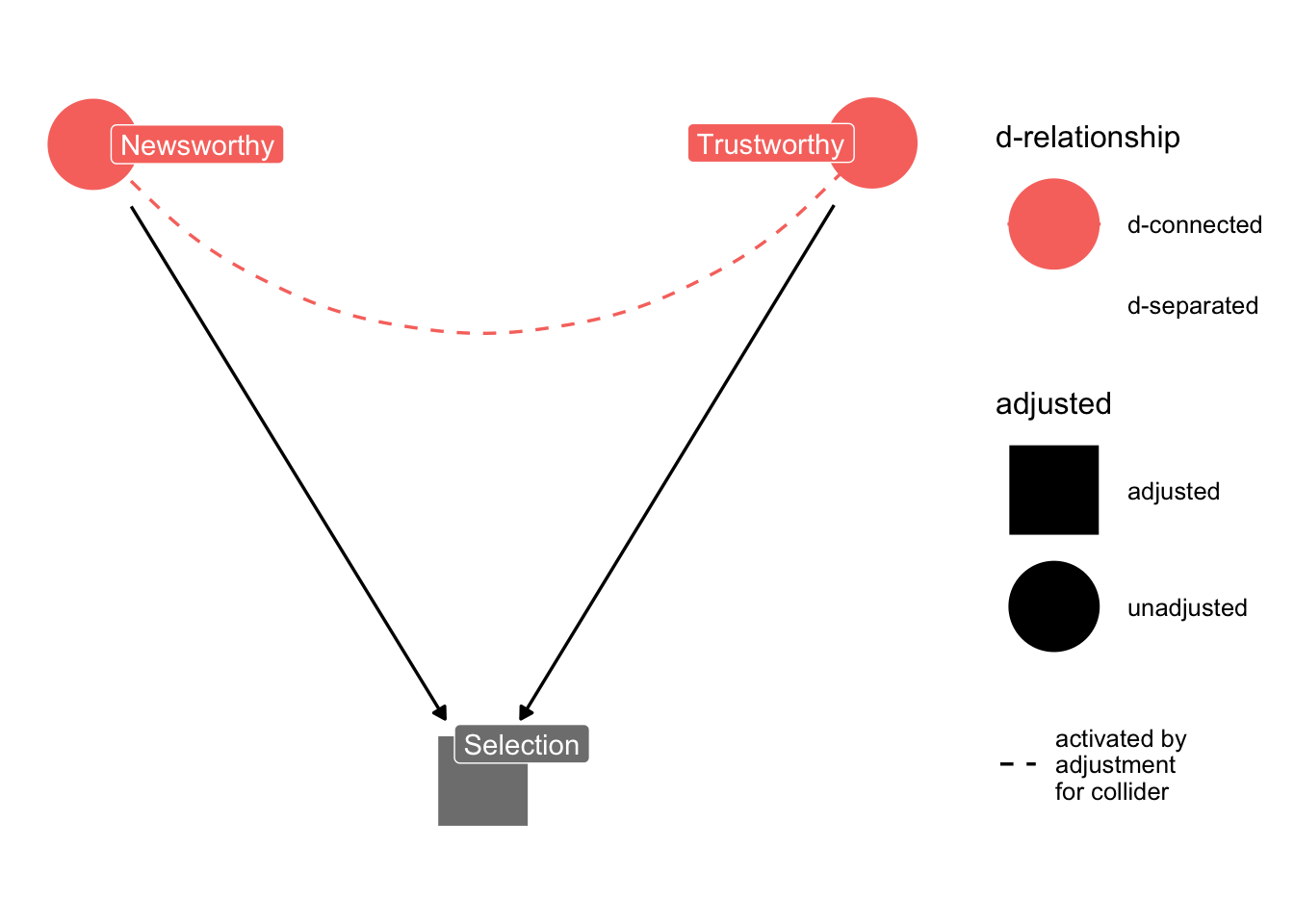
When two arrows enter into an variable, it opens a path of information between the two variables.
Very often this openning of information has disasterous implications. *In the human sciences, included variable bias is a woefully underrated problem*.
```{r code_folding = TRUE}
ggdag_dseparated(
dag_sd,
from = "T",
to = "N",
controlling_for = "S",
text = FALSE,
use_labels = "label"
) + theme_dag_blank()
```
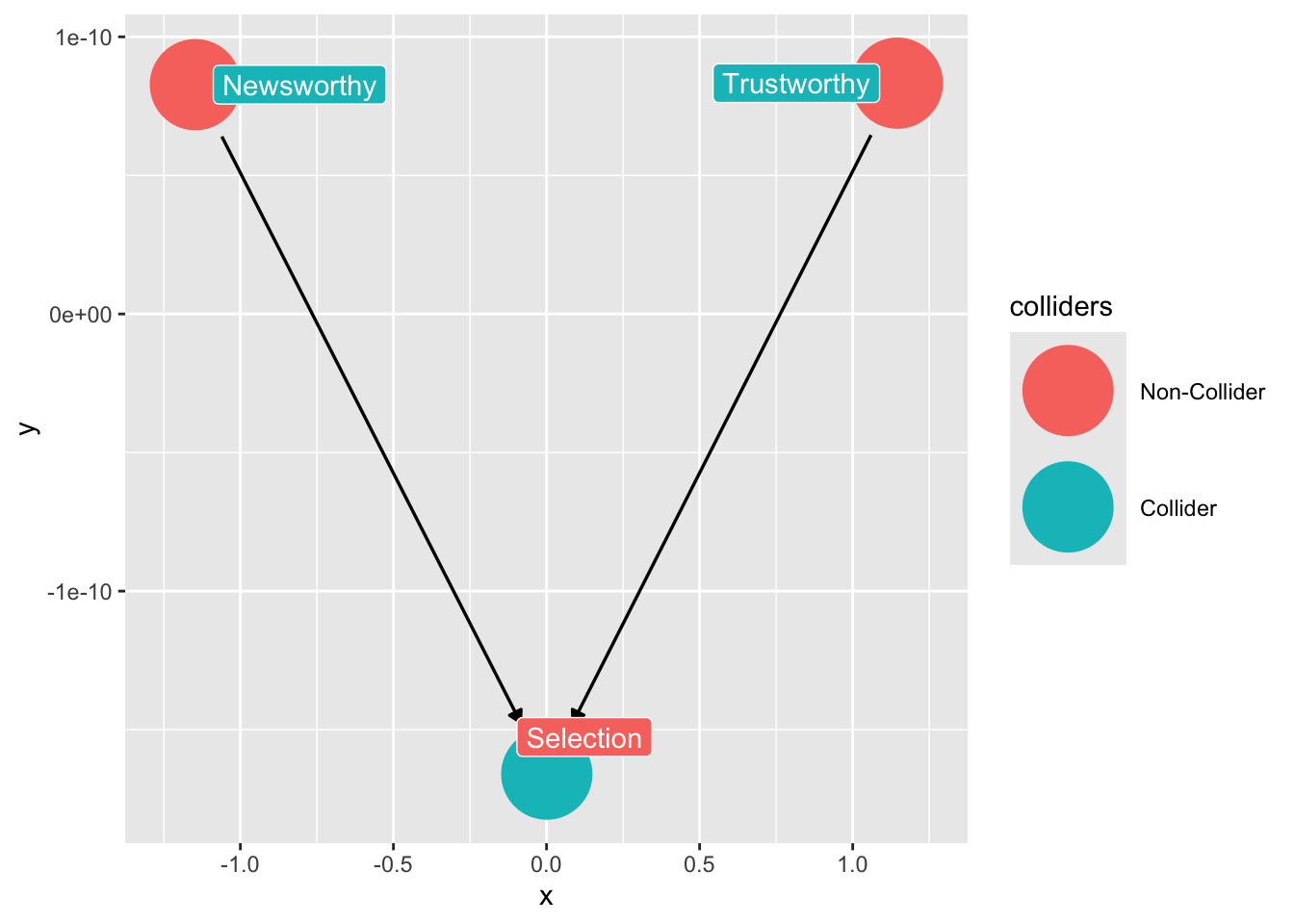
We can use the `ggdag package` to find colliders among our variables:
```{r}
# code for finding colliders
ggdag::ggdag_collider(dag_sd,
text = FALSE,
use_labels = "label")
```
The following simulation (by Solomon Kurz) illustrates the selection-distortion effect, which Richard McElreath discusses in *Statistical Rethinking*:
First simulated uncorrelated variables and a process of selection for sub-populations score high on both indicators.
```{r code_folding = TRUE}
# simulate selection distortion effect, following Solomon Kurz
# https://bookdown.org/content/4857/the-haunted-dag-the-causal-terror.html
set.seed(123)
n <- 1000 # number of grant proposals
p <- 0.05 # proportion to select
d <-
# uncorrelated newsworthiness and trustworthiness
dplyr::tibble(
newsworthiness = rnorm(n, mean = 0, sd = 1),
trustworthiness = rnorm(n, mean = 0, sd = 1)
) |>
# total_score
dplyr::mutate(total_score = newsworthiness + trustworthiness) |>
# select top 10% of combined scores
dplyr::mutate(selected = ifelse(total_score >= quantile(total_score, 1 - p), TRUE, FALSE))
```
Next filter out the high scoring examples, and assess their correlation.
Note that the act of selection *induces* a correlation within our dataset.
```{r}
d |>
dplyr::filter(selected == TRUE) |>
dplyr::select(newsworthiness, trustworthiness) |>
cor()
```
This makes it seems as if there is a relationship between Trustworthiness and Newsworthiness in science, even when there isn't any.
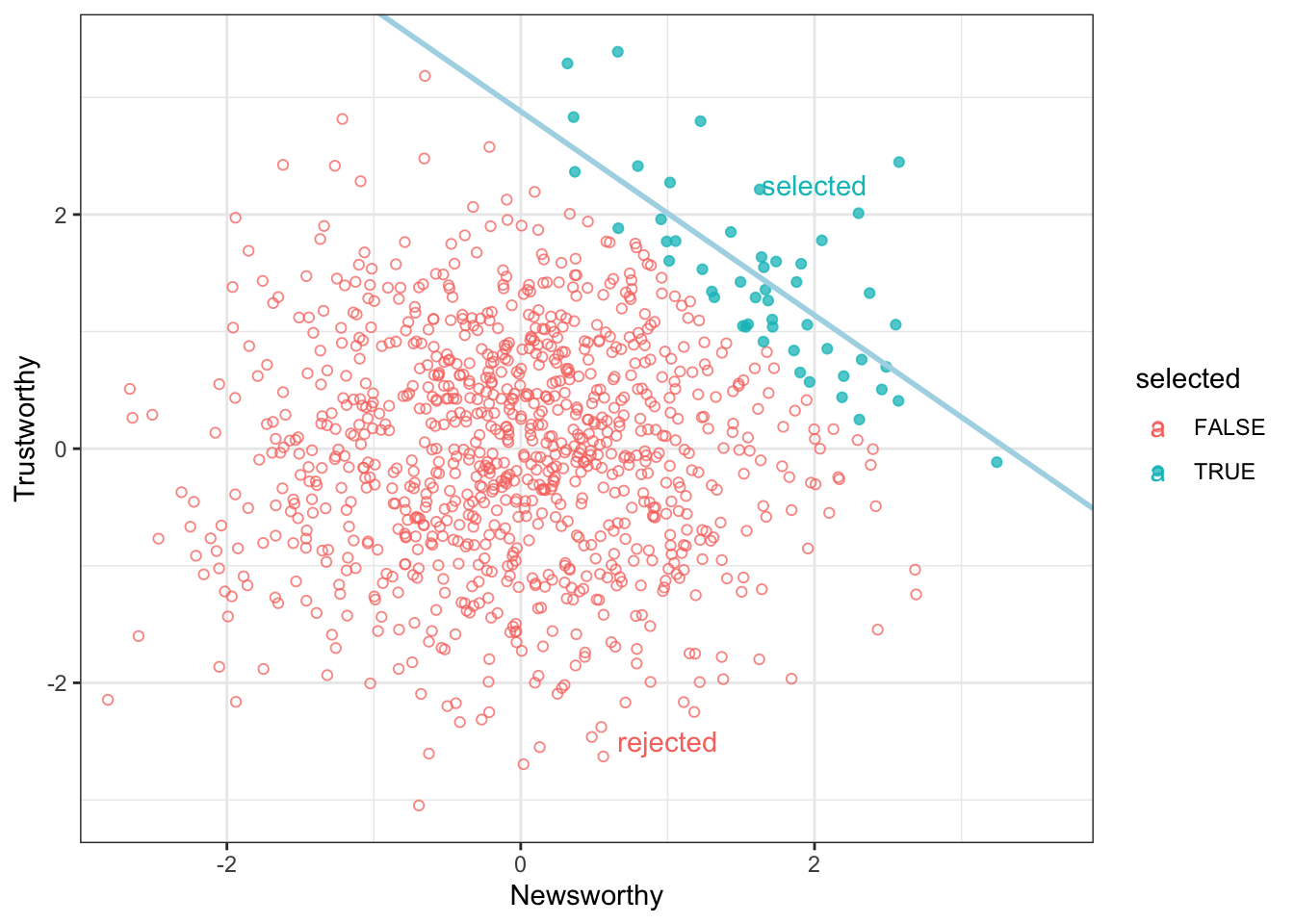
```{r code_folding = TRUE}
# we'll need this for the annotation
library(ggplot2)
text <-
dplyr::tibble(
newsworthiness = c(2, 1),
trustworthiness = c(2.25, -2.5),
selected = c(TRUE, FALSE),
label = c("selected", "rejected")
)
d |>
ggplot2::ggplot(aes(x = newsworthiness, y = trustworthiness, color = selected)) +
ggplot2::geom_point(aes(shape = selected), alpha = 3 / 4) +
ggplot2::geom_text(data = text,
aes(label = label)) +
ggplot2::geom_smooth(
data = d |> filter(selected == TRUE),
method = "lm",
fullrange = T,
color = "lightblue",
se = F,
size = 1
) +
# scale_color_manual(values = c("black", "lightblue")) +
ggplot2::scale_shape_manual(values = c(1, 19)) +
ggplot2::scale_x_continuous(limits = c(-3, 3.9), expand = c(0, 0)) +
ggplot2::coord_cartesian(ylim = range(d$trustworthiness)) +
ggplot2::theme(legend.position = "none") +
ggplot2::xlab("Newsworthy") +
ggplot2::ylab("Trustworthy") + theme_bw()
```
Once we know a proposal has been selected, if it is newsworthy we can predict that it is less trustworthy. Our simulation produces this prediction even though we simulated a world in which there is no relationship between trustworthiness and newsworthiness.
Selection bias is commonplace.
## Collider bias within experiments
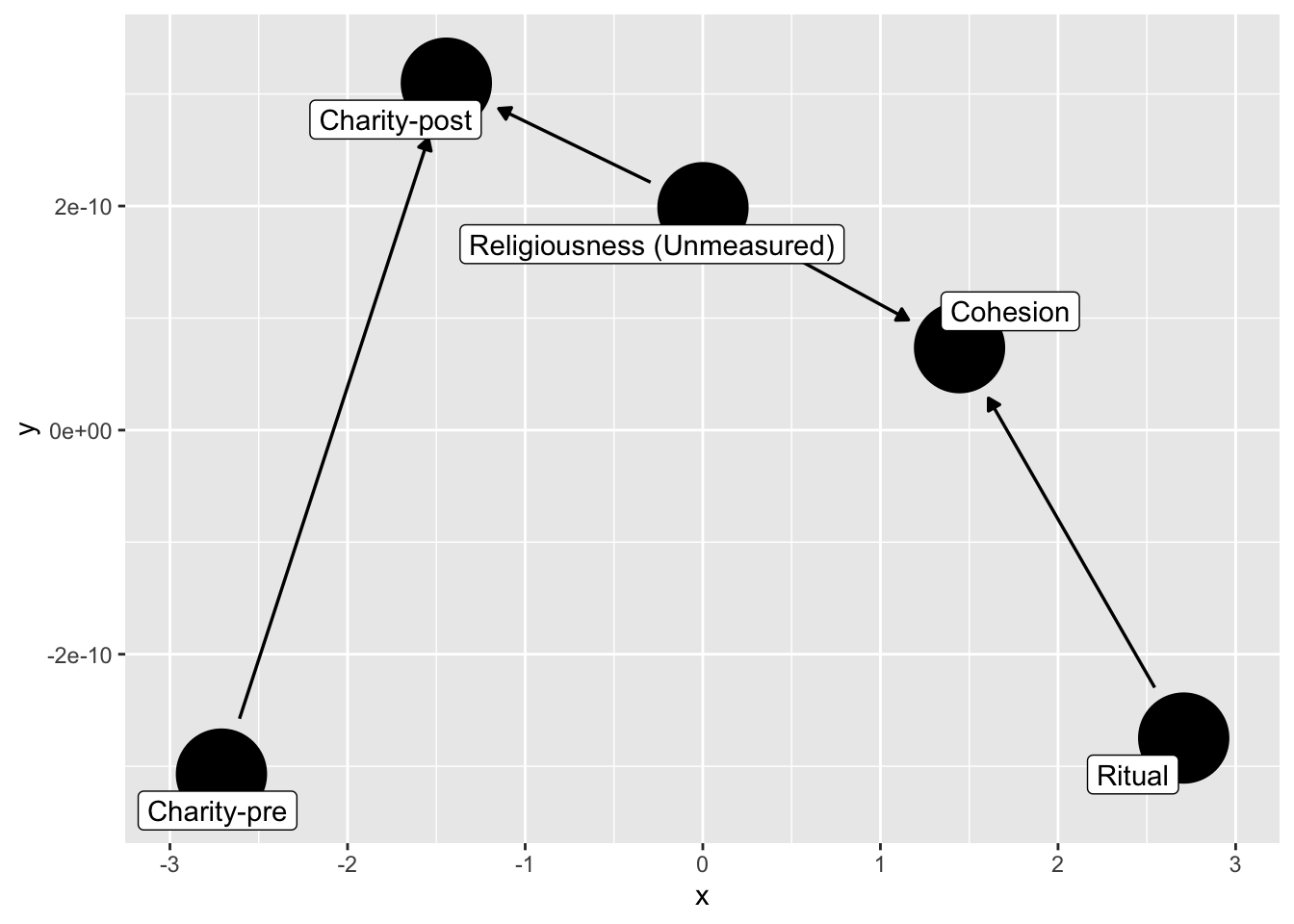
We noted that conditioning on a post-treatment variable can induce bias by blocking the path between the experimental manipulation and the outcome. However, such conditioning can open a path even when there is no experimental effect.
```{r code_folding = TRUE}
dag_ex2 <- dagify(
C1 ~ C0 + U,
Ch ~ U + R,
labels = c(
"R" = "Ritual",
"C1" = "Charity-post",
"C0" = "Charity-pre",
"Ch" = "Cohesion",
"U" = "Religiousness (Unmeasured)"
),
exposure = "R",
outcome = "C1",
latent = "U"
) |>
control_for(c("Ch","C0"))
dag_ex2 |>
ggdag( text = FALSE,
use_labels = "label")
```
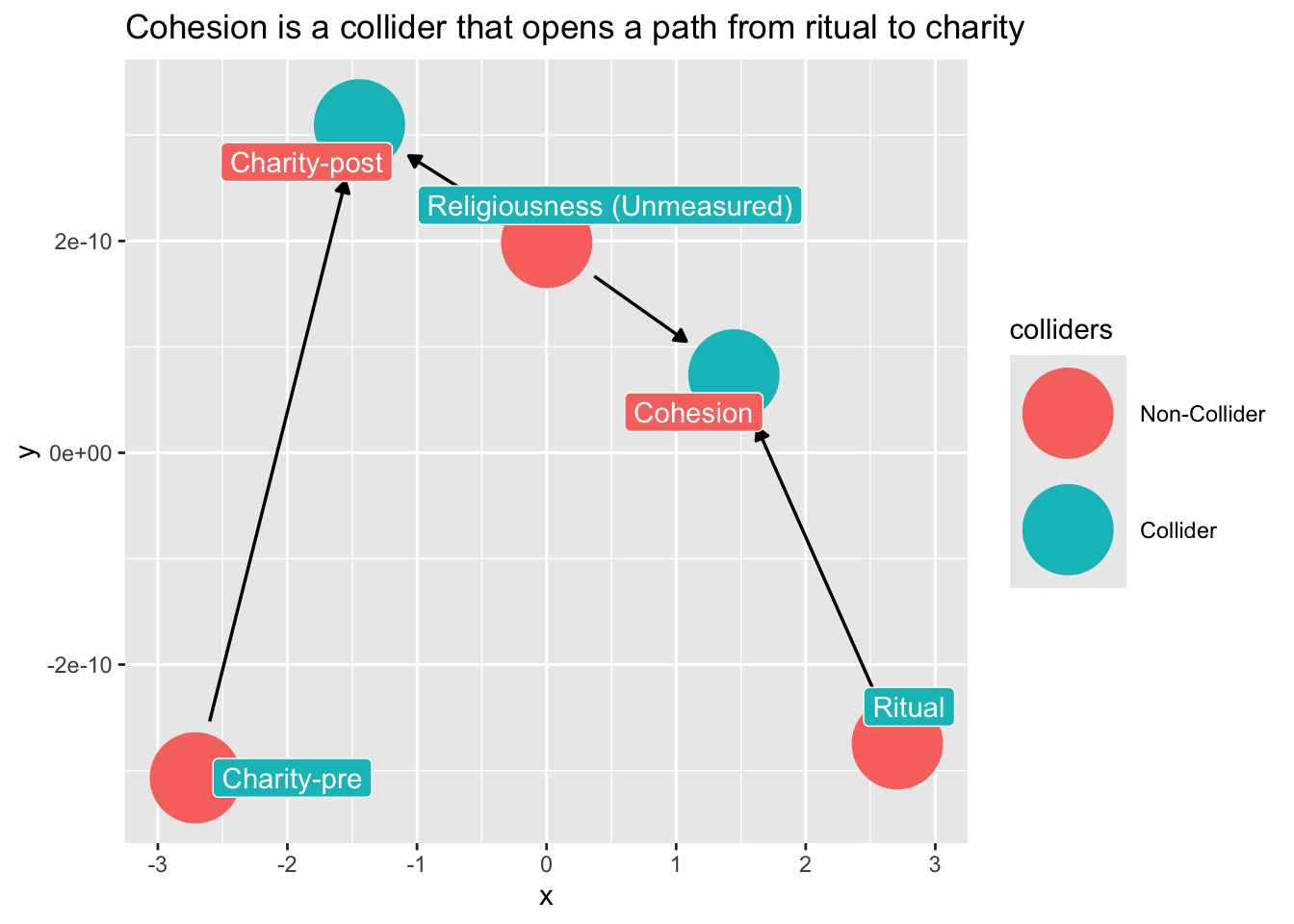
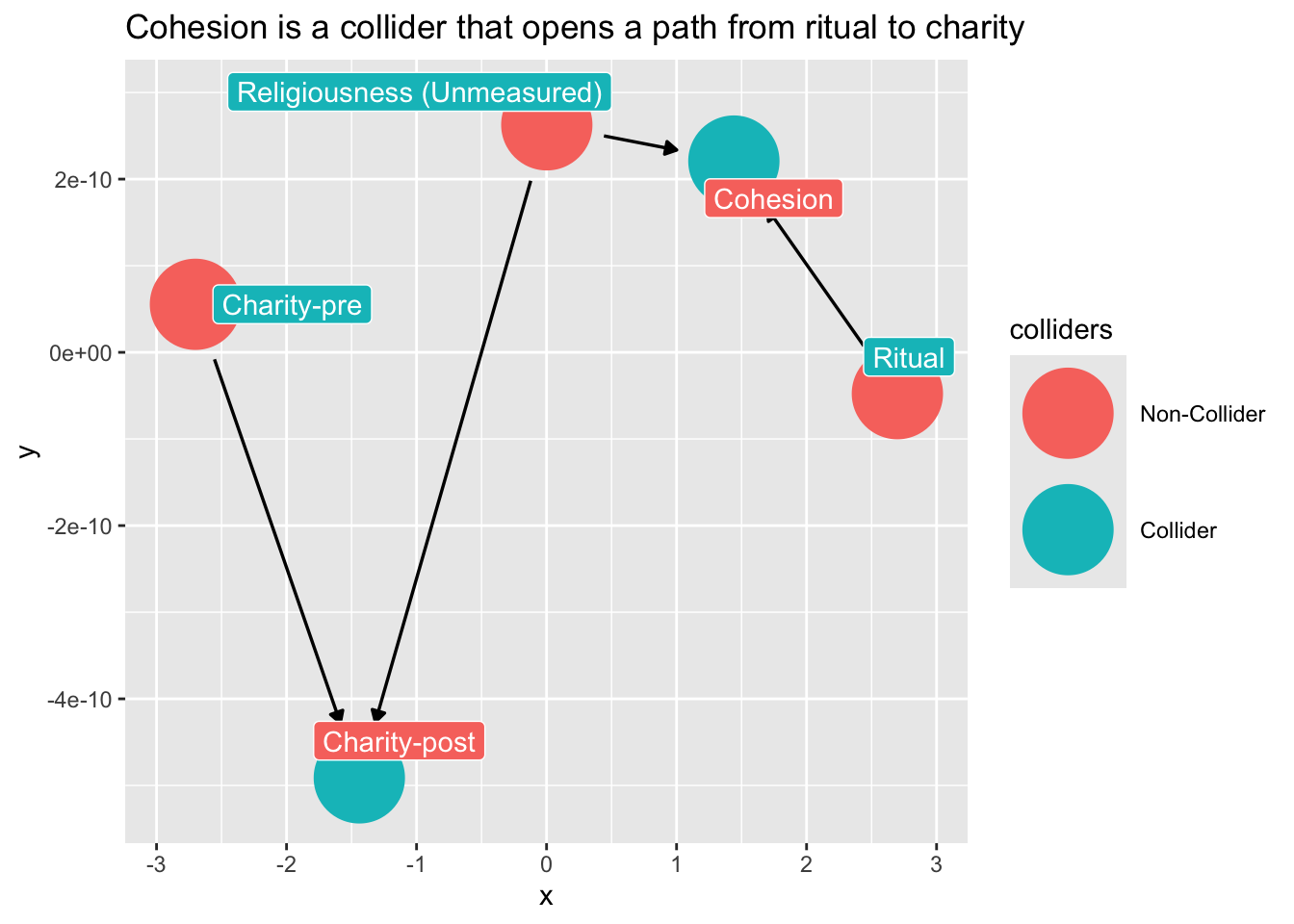
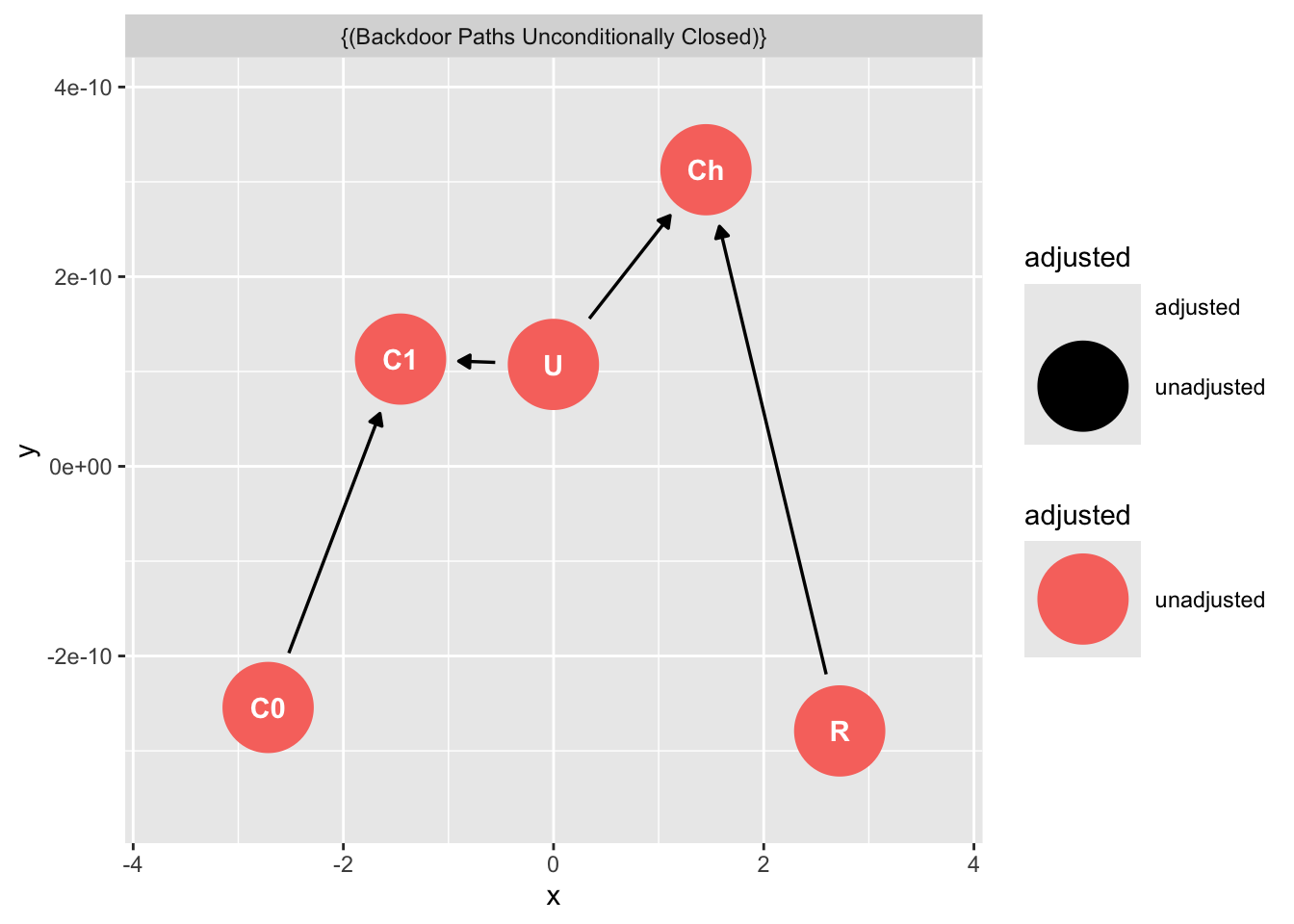
How do we avoid collider-bias here?
Note what happens if we condition on cohesion?
```{r}
dag_ex2 |>
ggdag_collider(
text = FALSE,
use_labels = "label"
) +
ggtitle("Cohesion is a collider that opens a path from ritual to charity")
```
Don't condition on a post-treatment variable!
```{r}
dag_ex3 <- dagify(
C1 ~ C0,
C1 ~ U,
Ch ~ U + R,
labels = c(
"R" = "Ritual",
"C1" = "Charity-post",
"C0" = "Charity-pre",
"Ch" = "Cohesion",
"U" = "Religiousness (Unmeasured)"
),
exposure = "R",
outcome = "C1",
latent = "U"
)
ggdag_adjustment_set(dag_ex3)
```
## Taxonomy of confounding
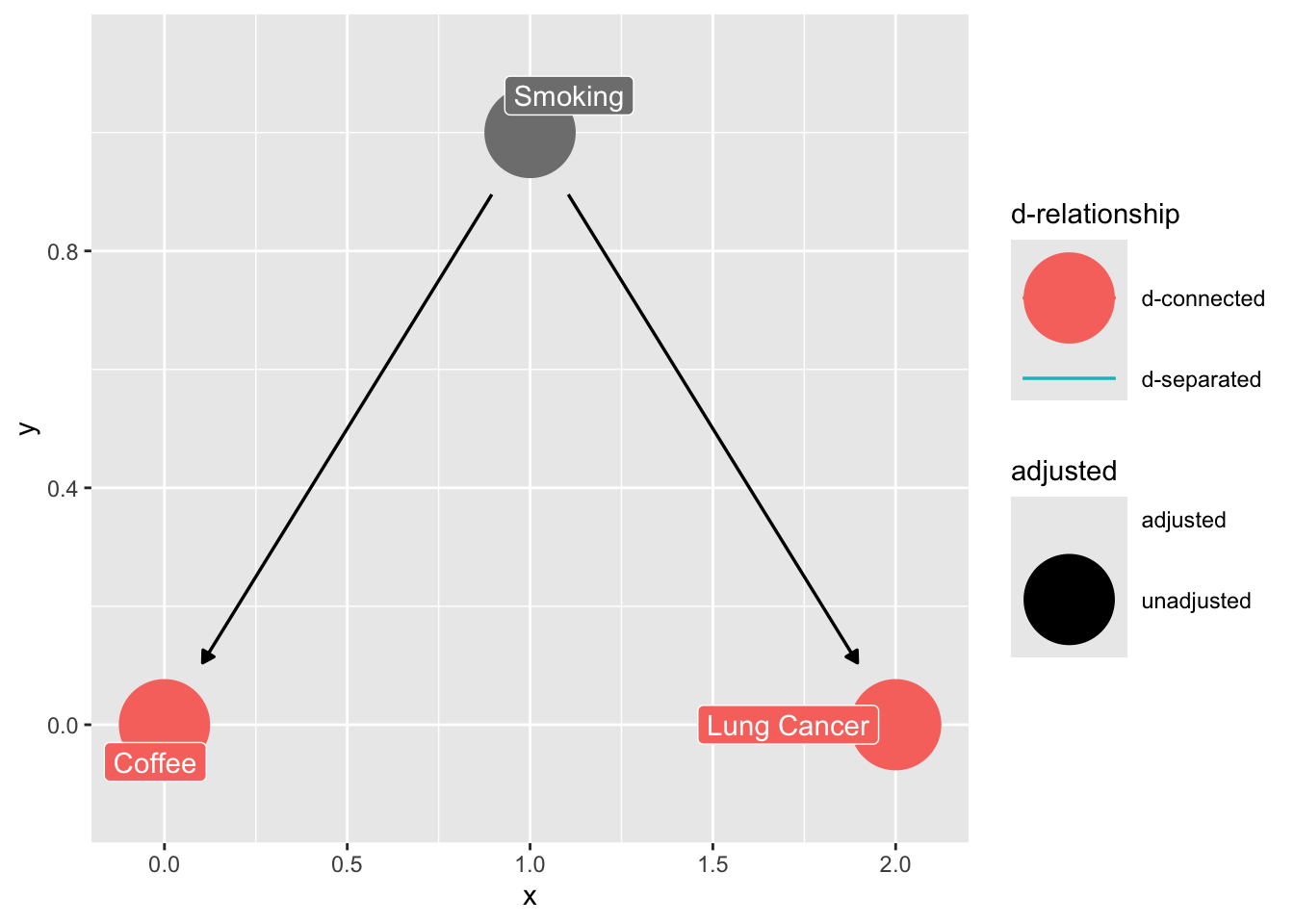
There is good news. Remember, ultimately are only four basic types of confounding:
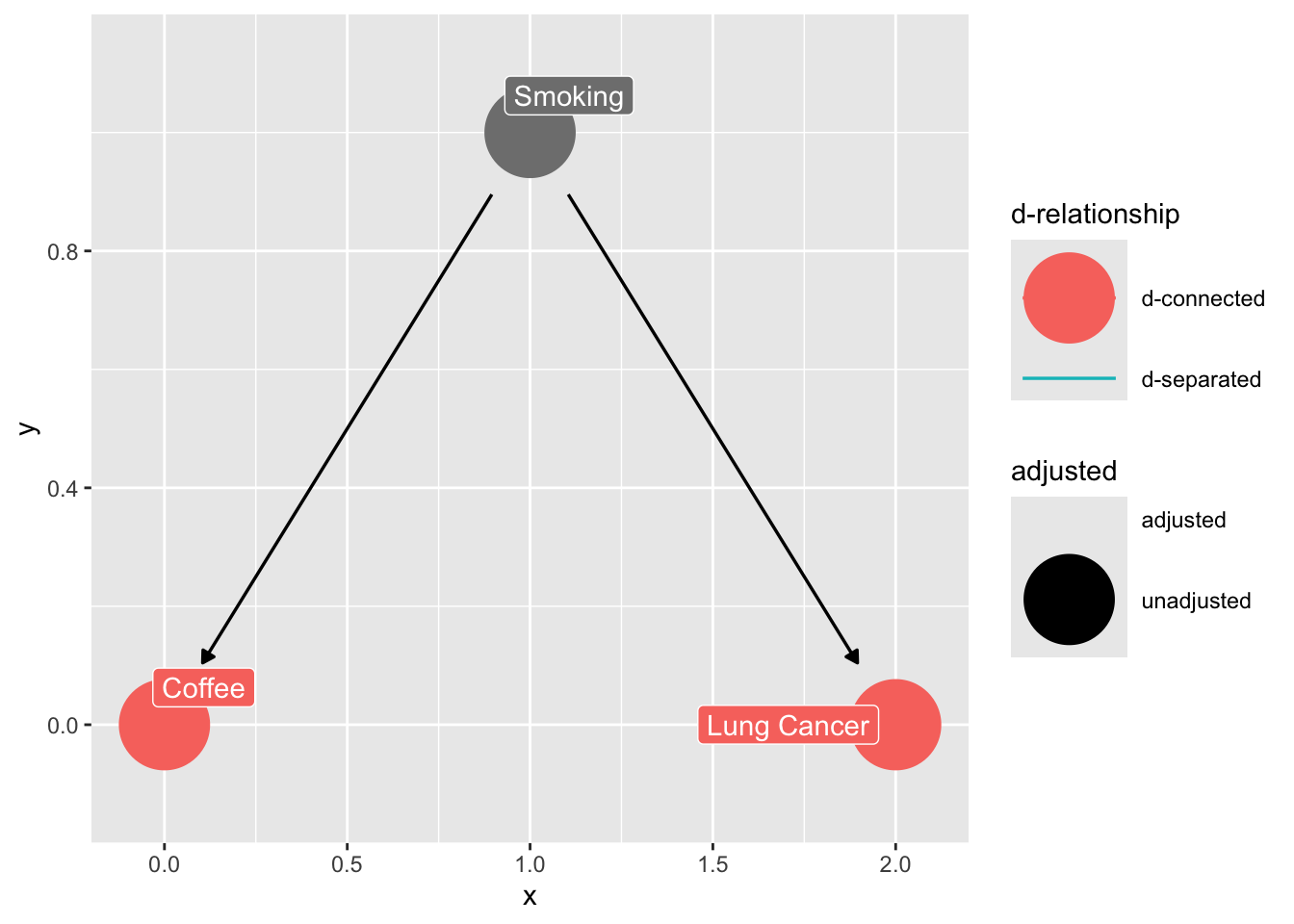
### The Fork (omitted variable bias)
```{r}
confounder_triangle(x = "Coffee",
y = "Lung Cancer",
z = "Smoking") |>
ggdag_dconnected(text = FALSE,
use_labels = "label")
```
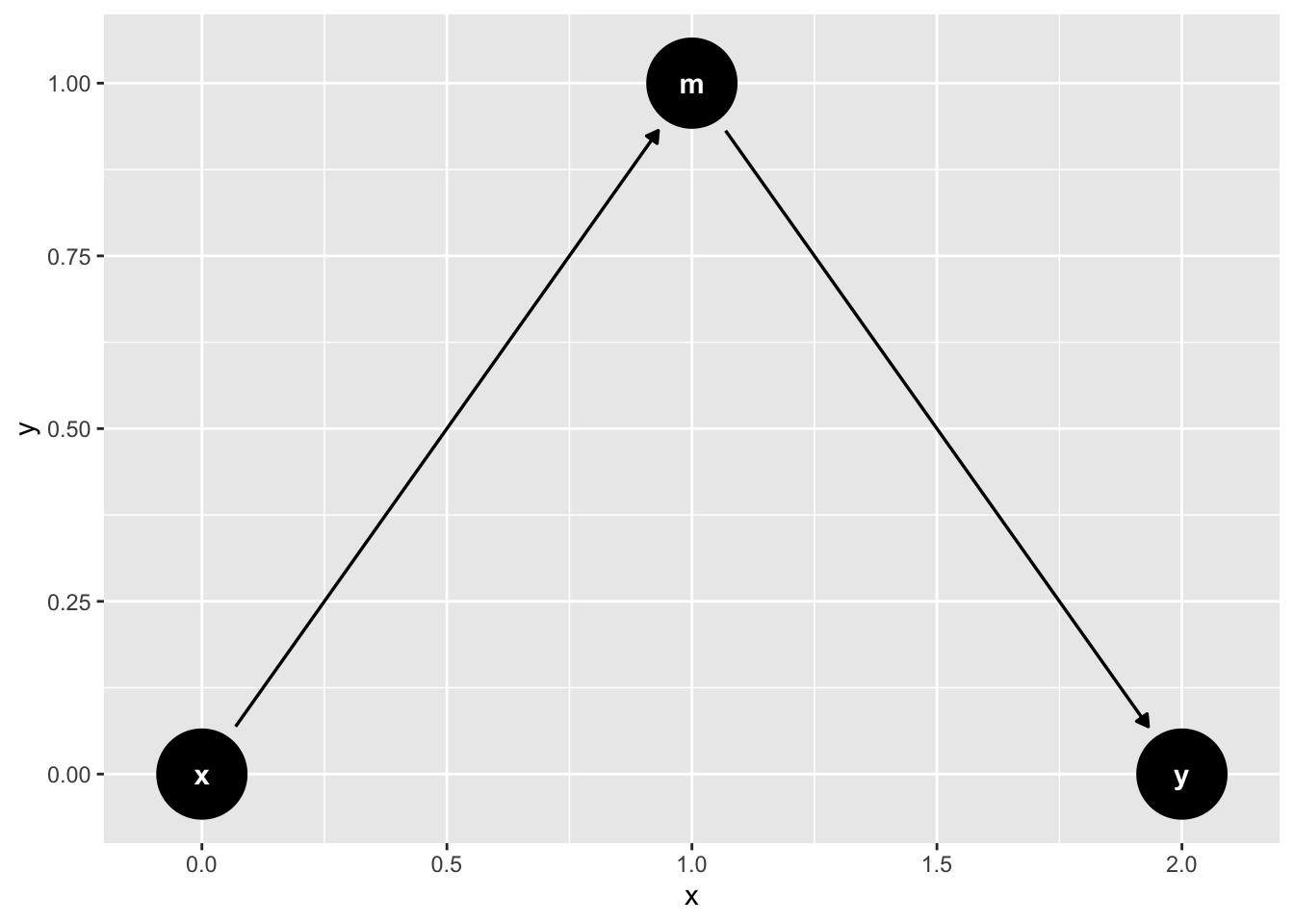
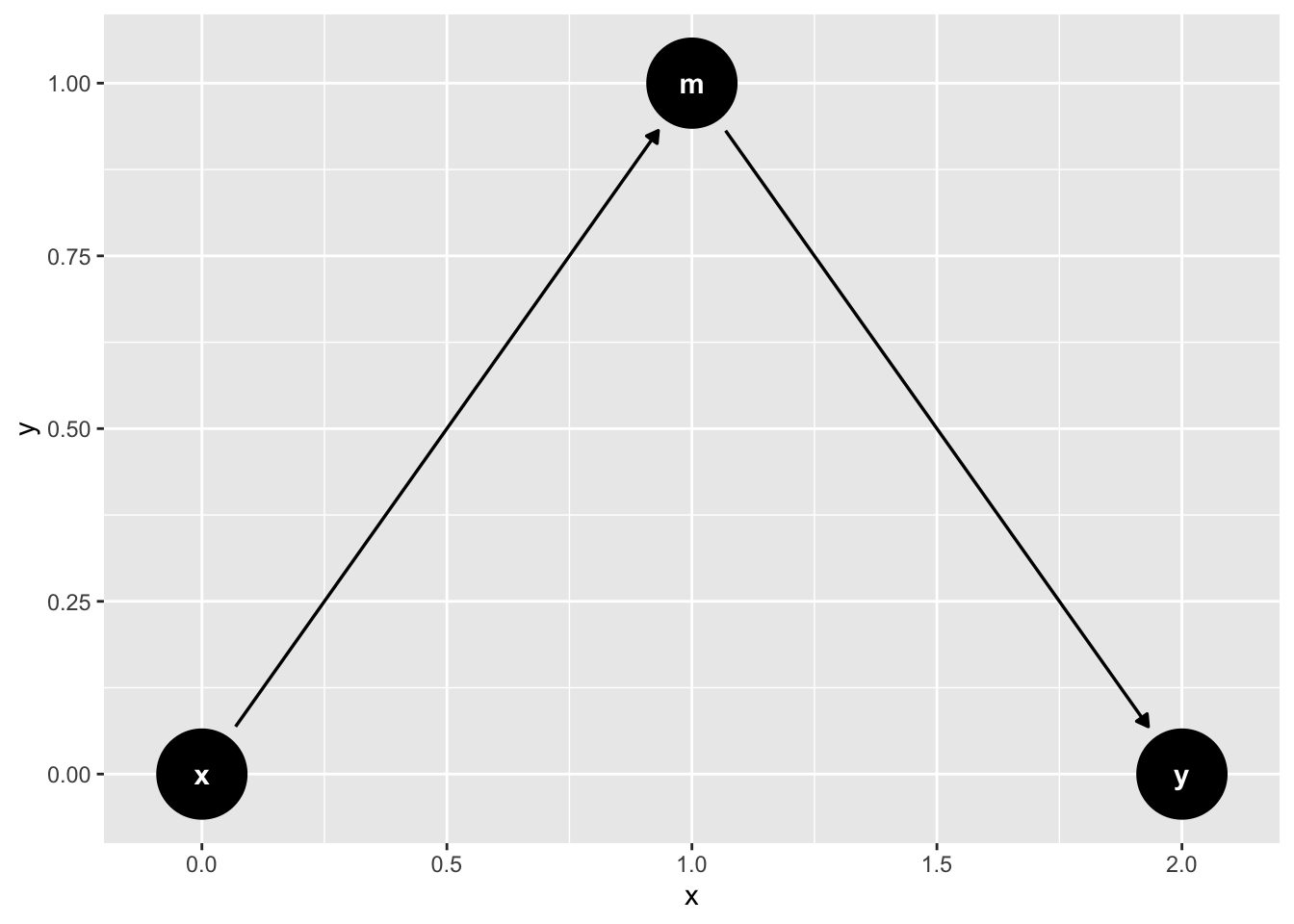
### The Pipe (fully mediated effects)
```{r}
mediation_triangle(
x = NULL,
y = NULL,
m = NULL,
x_y_associated = FALSE
) |>
tidy_dagitty(layout = "nicely") |>
ggdag()
```
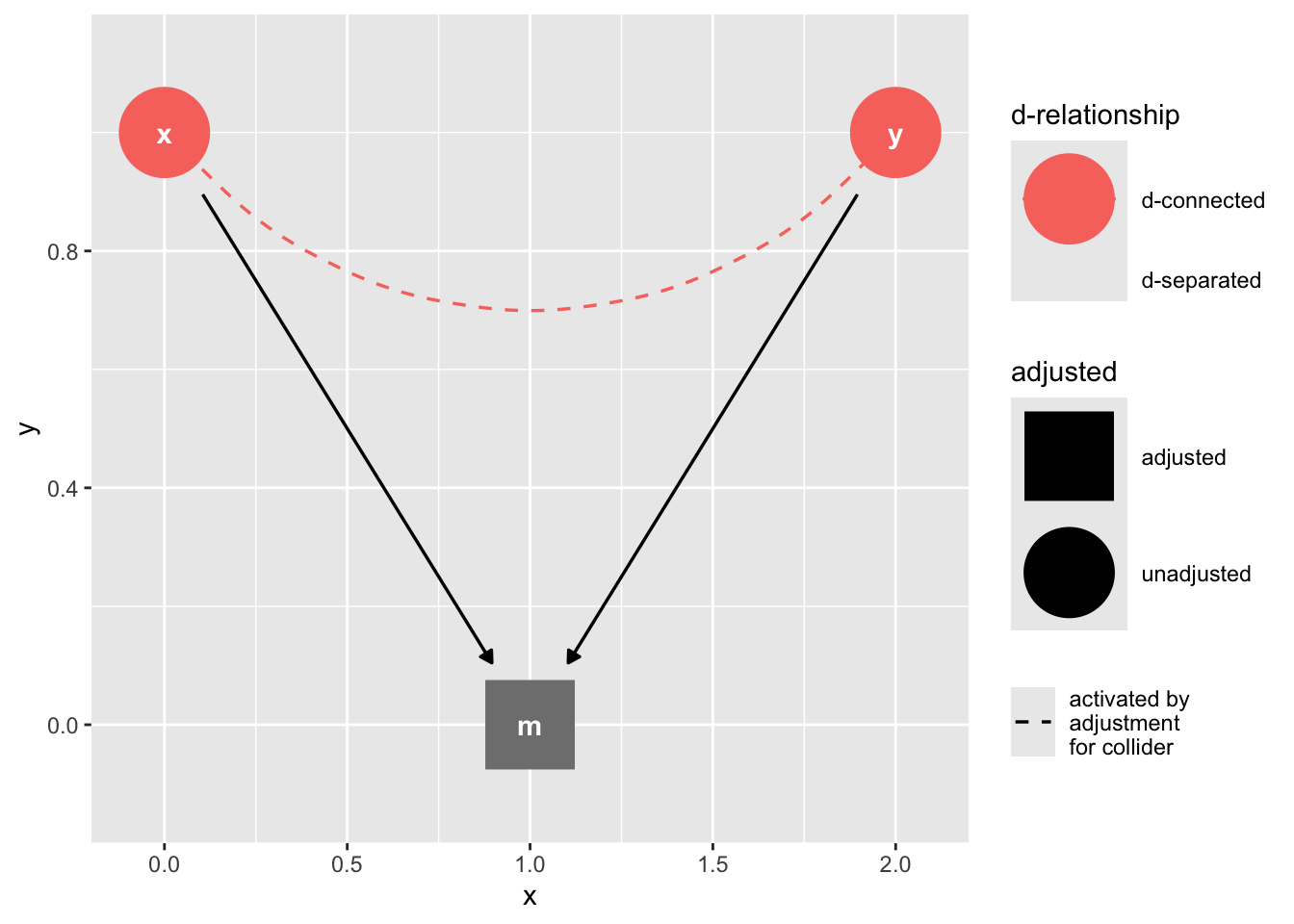
### The Collider
```{r}
collider_triangle() |>
ggdag_dseparated(controlling_for = "m")
```
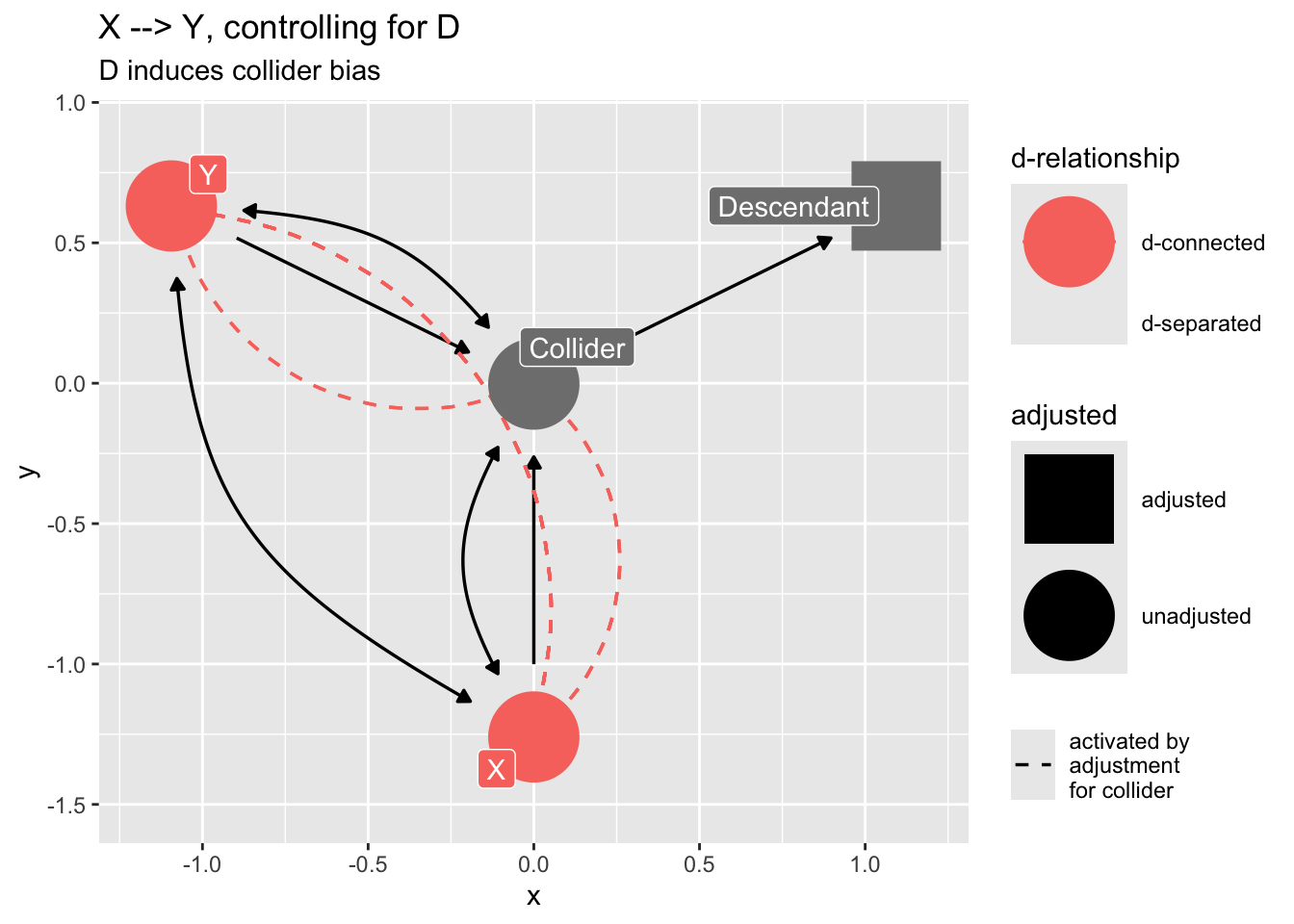
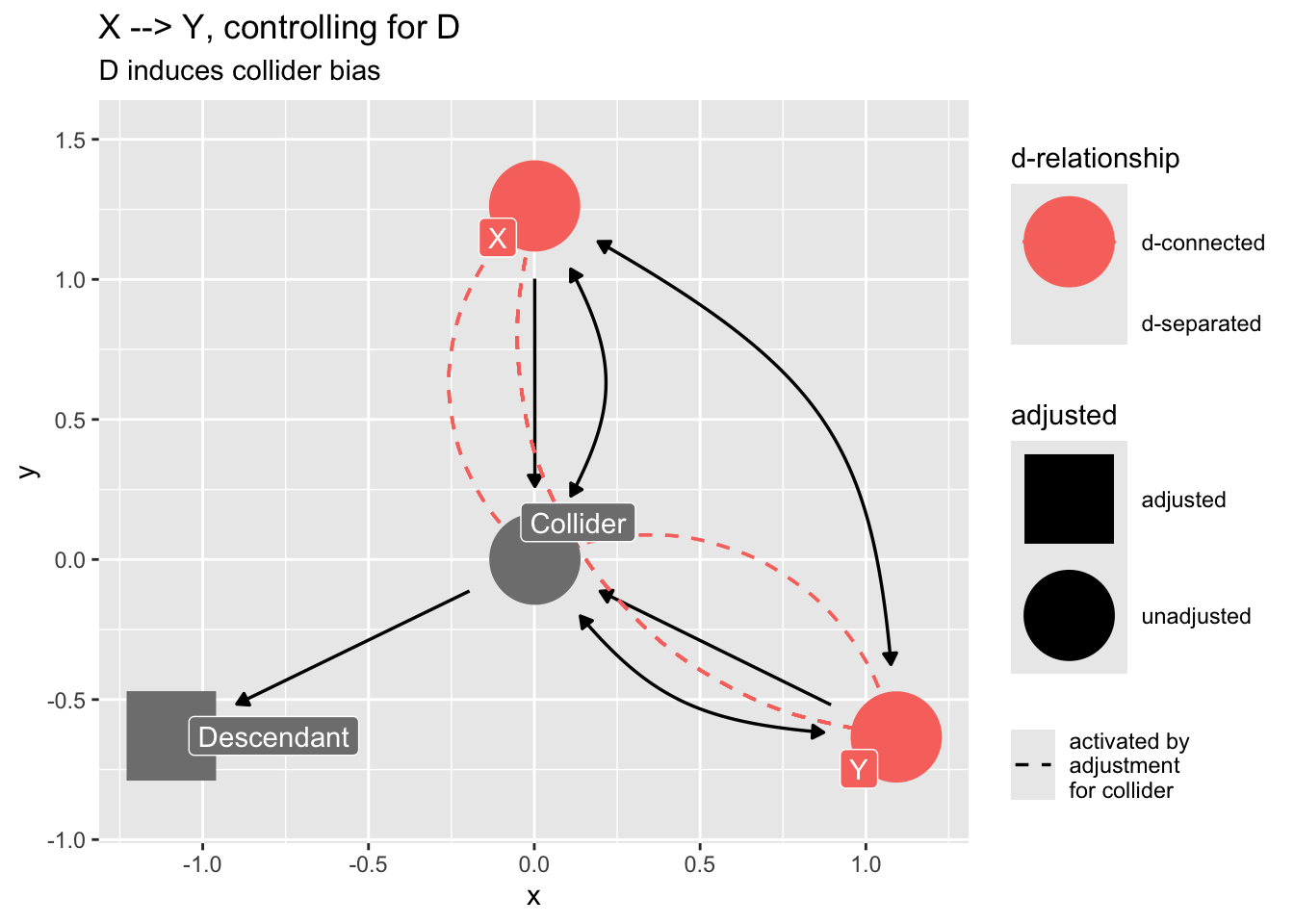
### Confounding by proxy
If we "control for" a descendant of a collider, we will introduce collider bias.
```{r}
dag_sd <- dagify(
Z ~ X,
Z ~ Y,
D ~ Z,
labels = c(
"Z" = "Collider",
"D" = "Descendant",
"X" = "X",
"Y" = "Y"
),
exposure = "X",
outcome = "Y"
) |>
control_for("D")
dag_sd |>
ggdag_dseparated(
from = "X",
to = "Y",
controlling_for = "D",
text = FALSE,
use_labels = "label"
) +
ggtitle("X --> Y, controlling for D",
subtitle = "D induces collider bias")
```
## Rules for avoiding confounding
From *Statistical Rethinking*, p.286
> List all of the paths connecting X (the potential cause of interest) and Y (the outcome).
> Classify each path by whether it is open or closed. A path is open unless it contains a collider.
> Classify each path by whether it is a backdoor path. A backdoor path has an arrow entering X.
> If there are any open backdoor paths, decide which variable(s) to condition on to close it (if possible).
```{r}
# Examle
# call ggdag model
# write relationships:
library(ggdag)
dg_1 <- ggdag::dagify(
b ~ im + ordr + rel + sr + st,
rel ~ age + ses + edu + male + cny,
ses ~ cny + edu + age,
edu ~ cny + male + age,
im ~ mem + rel + cny,
mem ~ age + edu + ordr,
exposure = "sr",
outcome = "b",
labels = c(
"b" = "statement credibility",
"sr" = "source",
"st" = "statement",
"im" = "importance",
"mem" = "memory",
"s" = "source",
"rel" = "religious",
"cny" = "country",
"mem" = "memory",
"male" = "male",
"ordr" = "presentation order",
"ses" = "perceived SES",
"edu" = "education",
"age" = "age"
)
) |>
control_for("rel")
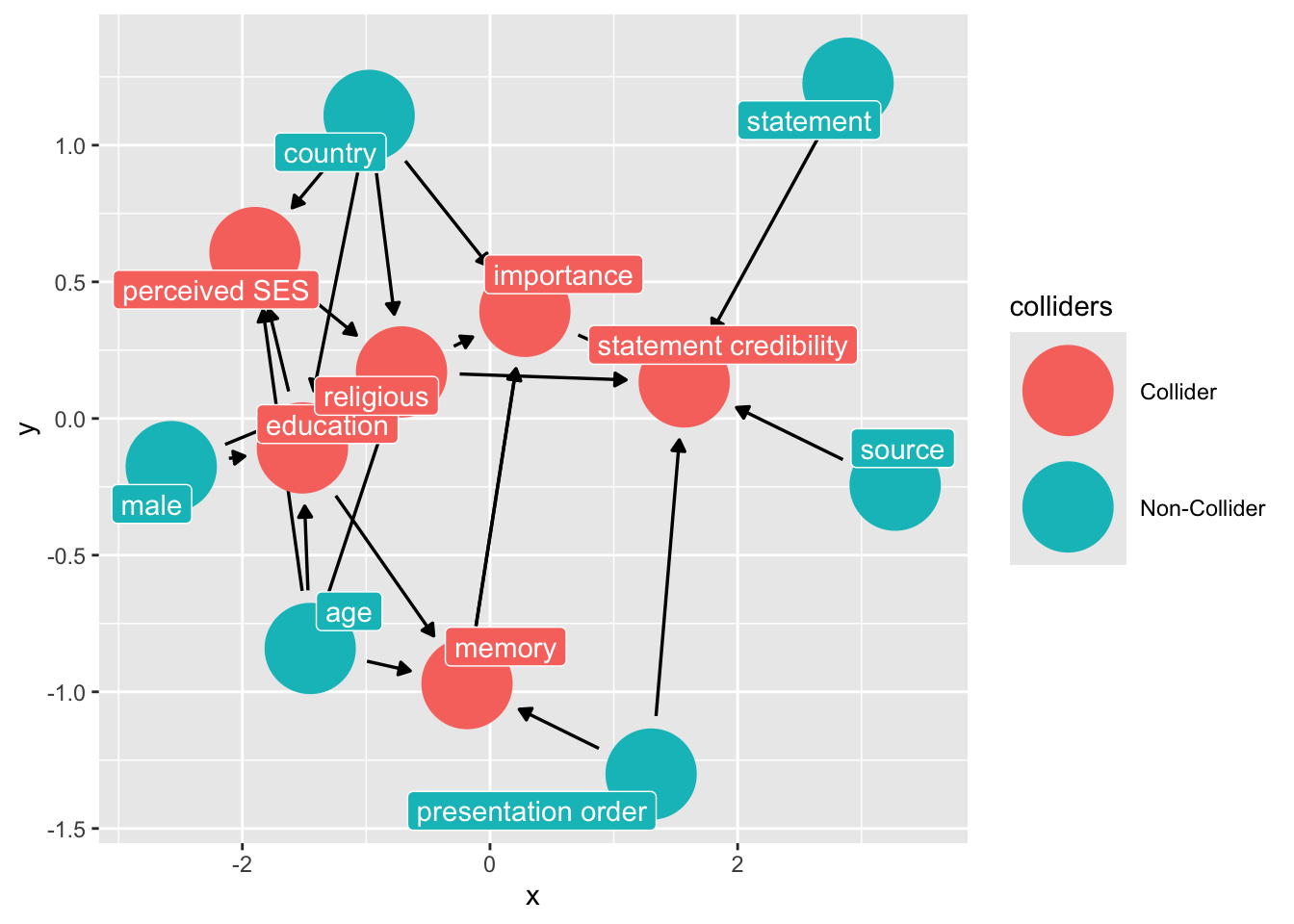
ggdag::ggdag_collider(dg_1, text = FALSE, use_labels = "label")
```
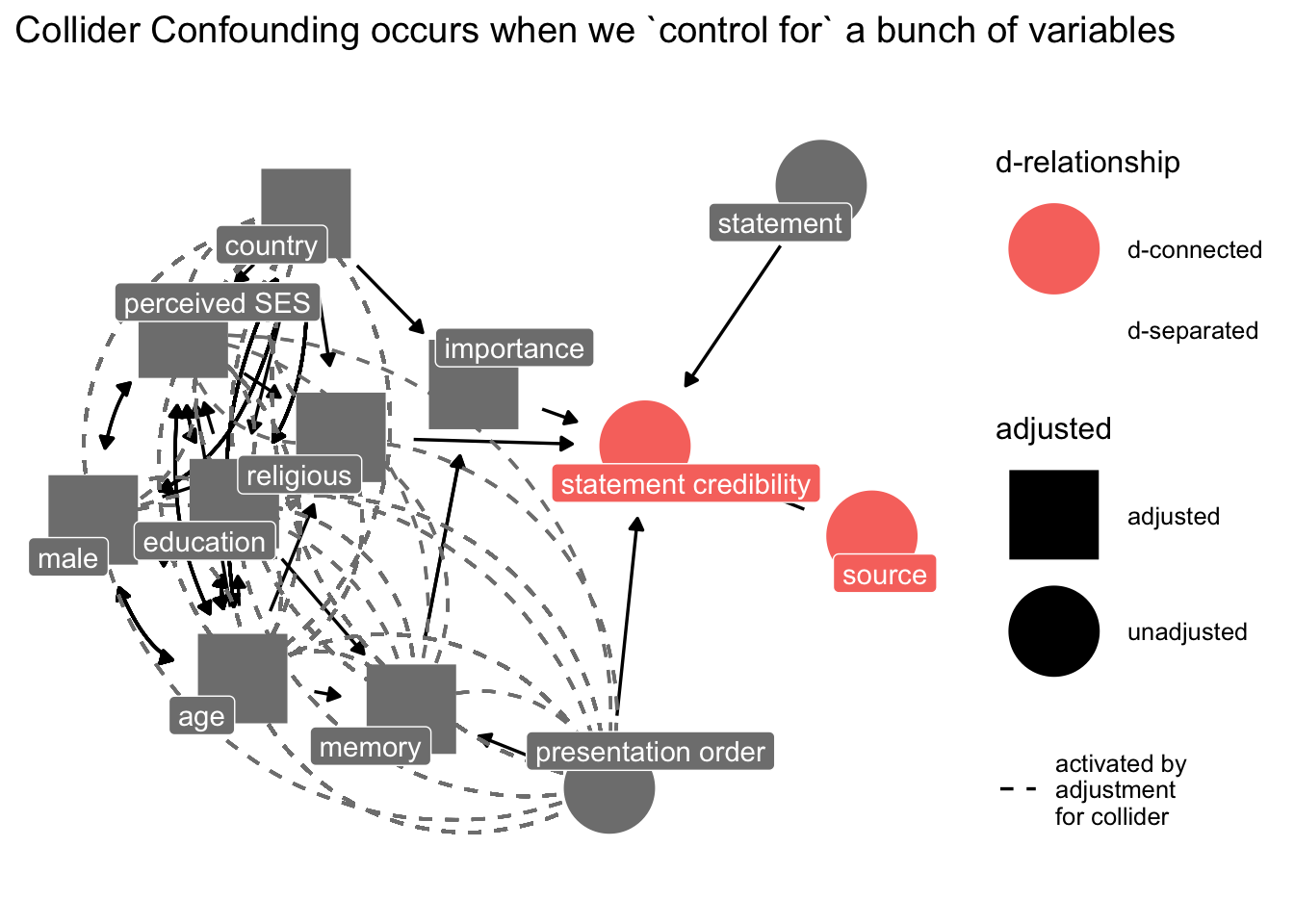
Note the colliders induced from the "controls" that we had included in the study:
```{r}
p3 <- ggdag::ggdag_dseparated(
dg_1,
from = "sr",
to = "b",
controlling_for = c("ses", "age", "cny", "im", "edu", "mem", "male", "rel"),
text = FALSE,
use_labels = "label"
) +
theme_dag_blank() +
labs(title = "Collider Confounding occurs when we `control for` a bunch of variables")
p3
```
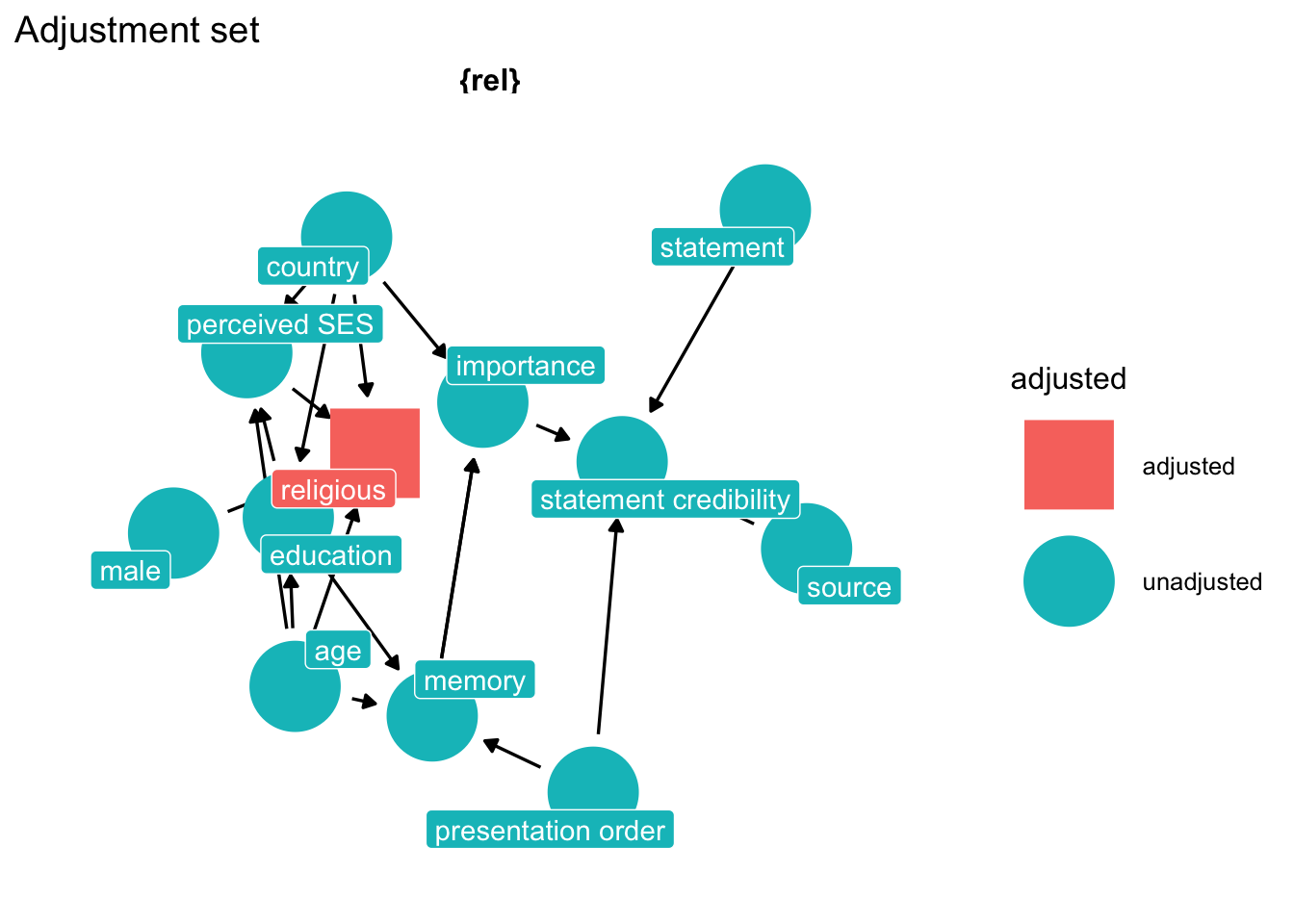
How do we fix the problem? Think hard about the causal network and let `ggdag` do the work.
```{r}
# find adjustment set
p2 <- ggdag::ggdag_adjustment_set(dg_1,
text = FALSE,
use_labels = "label") +
theme_dag_blank() +
labs(title = "Adjustment set",
subtite = "Model for Source credibility from belief ")
p2
```
## Inference depends on assumptions that are not contained in the data.
> regression itself does not provide the evidence you need to justify a causal model. Instead, you need some science." -- Richard McElreath: "Statistical Rethinking, Chapter 6"
> "...the data alone can never tell you which causal model is correct"- Richard McElreath: "Statistical Rethinking" Chapter 5
> "The parameter estimates will always depend upon what you believe about the causal model, because typically several (or very many) causal models are consistent with any one set of parameter estimates." "Statistical Rethinking" Chapter 5
Suppose we assume that the source condition affects religion, say through priming. We then have the following dag:
```{r}
## adding religion to effect on edu
dg_3 <- ggdag::dagify(
b ~ im + ordr + rel + st + sr,
rel ~ age + ses + edu + male + cny + sr,
ses ~ cny + edu + age,
edu ~ cny + male + age,
im ~ mem + rel + cny,
mem ~ age + edu + ordr,
exposure = "rel",
outcome = "b",
labels = c(
"b" = "statement credibility",
"sr" = "source",
"st" = "statement",
"im" = "importance",
"mem" = "memory",
"s" = "source",
"rel" = "religious",
"cny" = "country",
"mem" = "memory",
"male" = "male",
"ordr" = "presentation order",
"ses" = "perceived SES",
"edu" = "education",
"age" = "age"
)
)|>
control_for("rel")
ggdag(dg_3, text = FALSE, use_labels = "label")
```
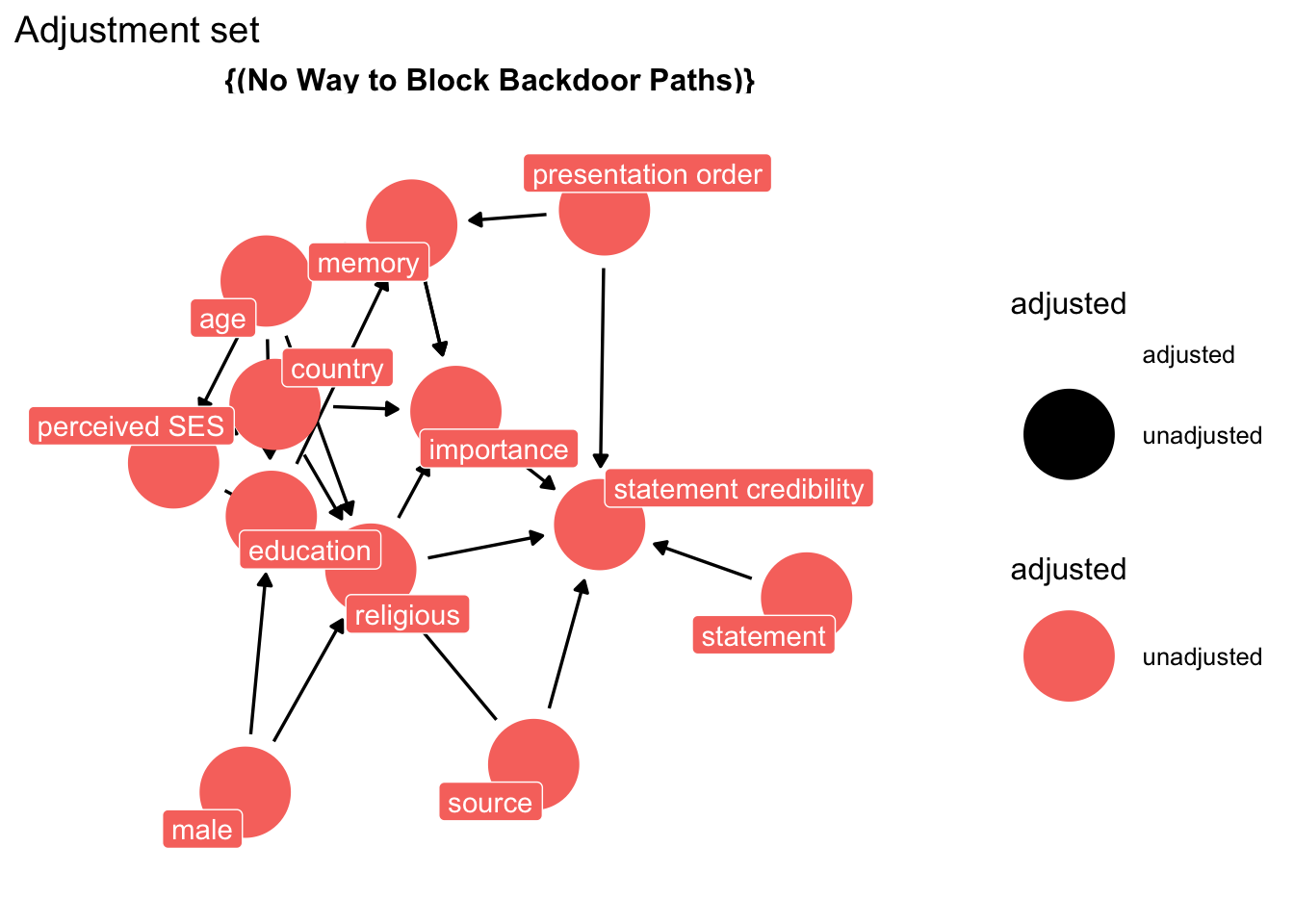
We turn to our trusted oracle, and and ask: "What do we condition on to obtain an unbiased causal estimate?"
The oracle replies:
```{r}
ggdag::ggdag_adjustment_set(
dg_3,
exposure = "sr",
outcome = "b",
text = FALSE,
use_labels = "label"
) +
theme_dag_blank() +
labs(title = "Adjustment set",
subtite = "Model for Source credibility from belief ")
```
Your data cannot answer your question.
## More examples of counfounding/de-confounding
Here's another example from recent NZAVS research
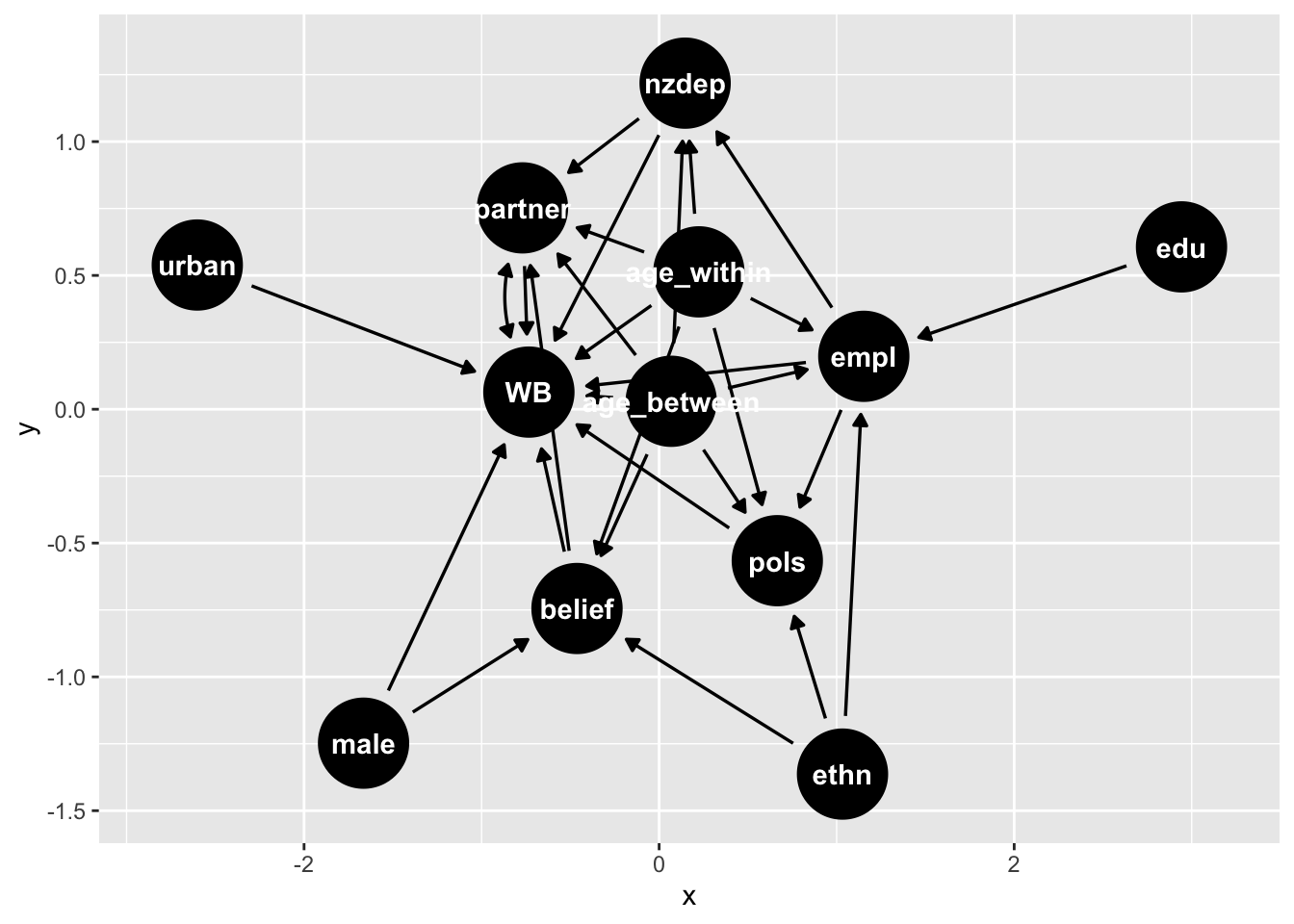
```{r}
tidy_ggdag <- dagify(
WB ~ belief + age_within + age_between + partner + nzdep + urban + male + pols + empl,
WB ~~ partner,
belief ~ age_within + age_between + male + ethn,
partner ~ nzdep + age_within + age_between + belief,
nzdep ~ empl + age_within + age_between,
pols ~ age_within + age_between + empl + ethn,
empl ~ edu + ethn + age_within + age_between,
exposure = "belief",
outcome = "WB")|>
tidy_dagitty()
# graph
tidy_ggdag |>
ggdag()
```
We can examine which variables to select, conditional on the causal assumptions of this dag
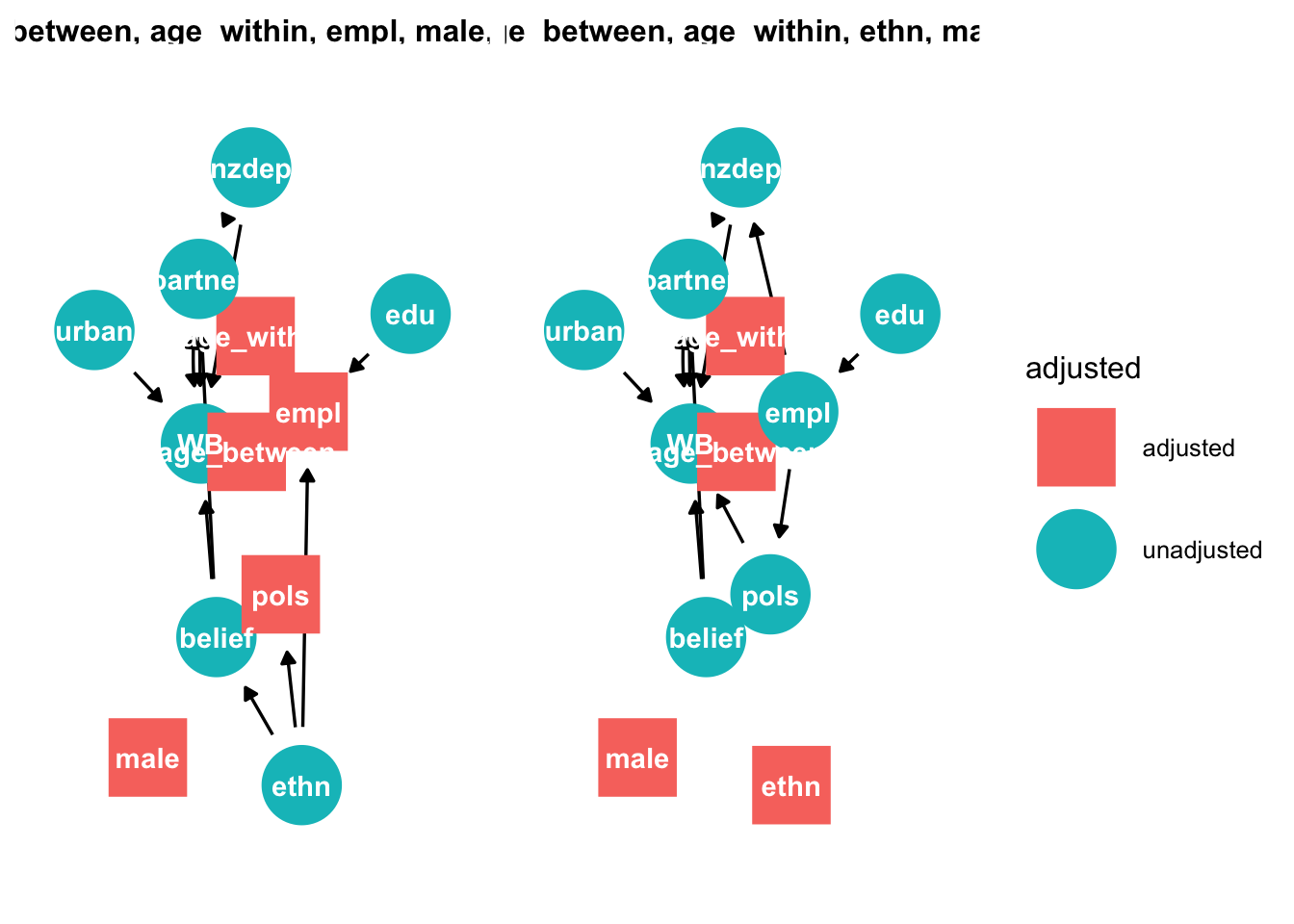
```{r}
# graph adjustment sets
ggdag::ggdag_adjustment_set(tidy_ggdag, node_size = 14) +
theme(legend.position = "bottom") + theme_dag_blank()
```
This method reveals two adjustments sets: {age, employment, male,
political conservativism, and time}, and {age, ethnicty, male, and
time.} We report the second set because employment is likely to contain
more measurement error: some are not employed because they cannot find
employment, others because they are not seeking employment (e.g.
retirement).
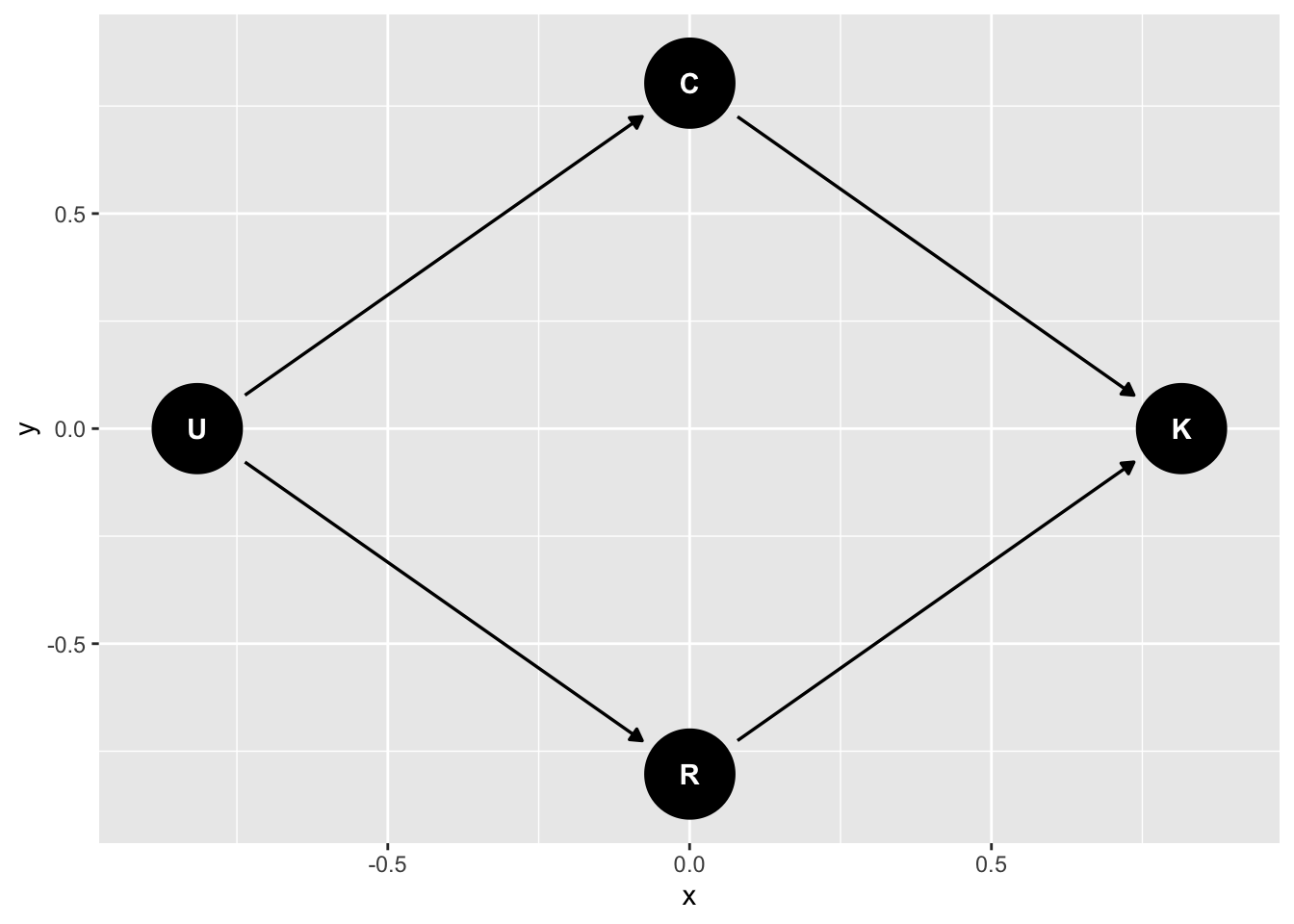
### Unmeasured causes
Return to the previous example of R and C on K6 distress, but imagine an underlying common cause of both C and R (say childhood upbringing) called "U":
```{r}
dag_m3 <- dagify(
K ~ C + R,
C ~ U,
R ~ U,
exposure = "C",
outcome = "K",
latent = "U"
) |>
tidy_dagitty(layout = "nicely")
dag_m3 |>
ggdag()
```
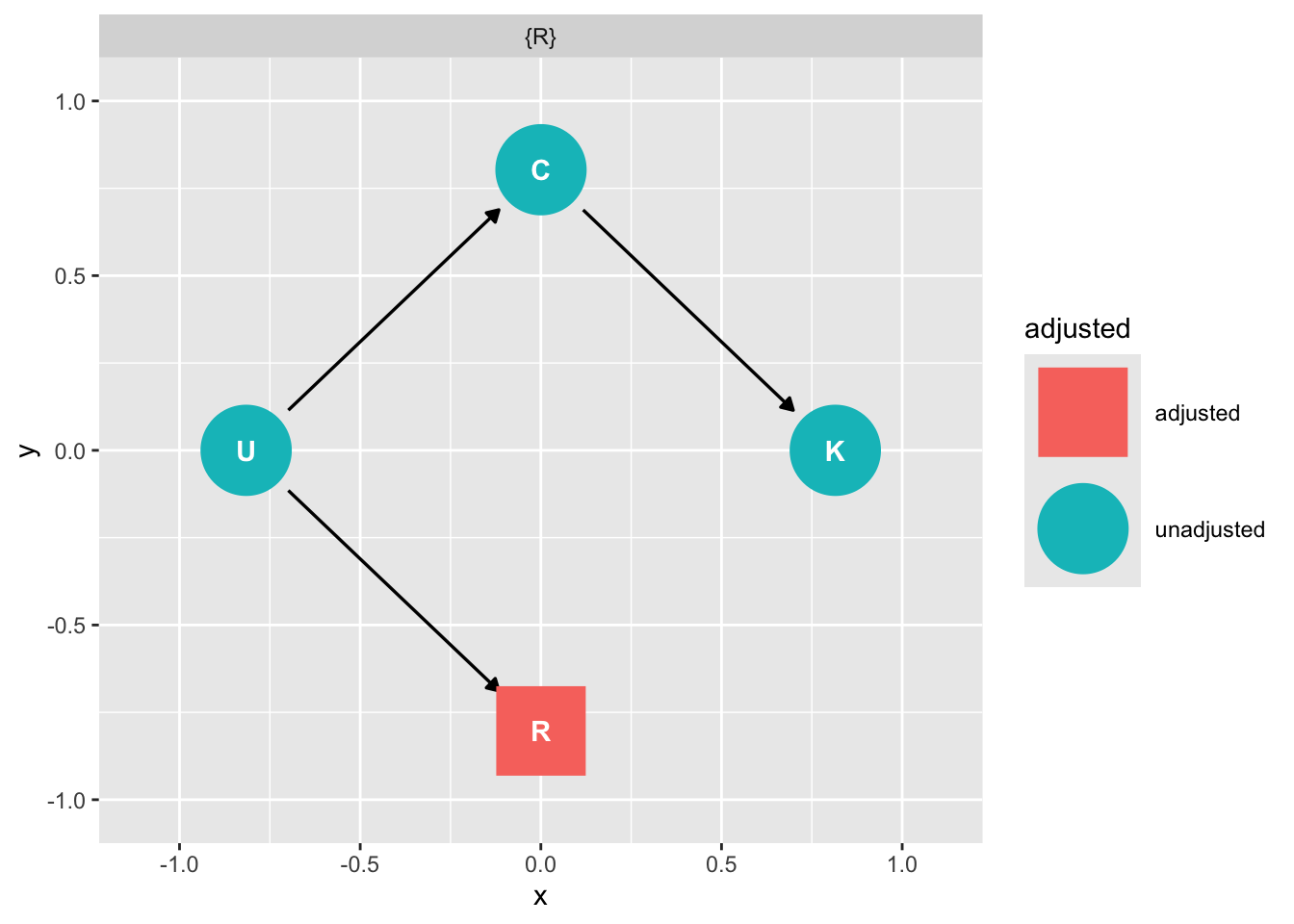
How do we assess the relationship of C on K?
We can close the backdoor from U through R by conditioning on R
```{r}
ggdag::ggdag_adjustment_set(dag_m3)
```
Aside, we can simulate this relationship using the following code:
```{r}
# C -> K <- R
# C <- U -> R
n <- 100
U <- rnorm( n )
R <- rnorm( n , U )
C <- rnorm( n , U )
K <- rnorm( n , R - C )
d_sim3 <- data.frame(K = K, R = R, U = U, C = C )
```
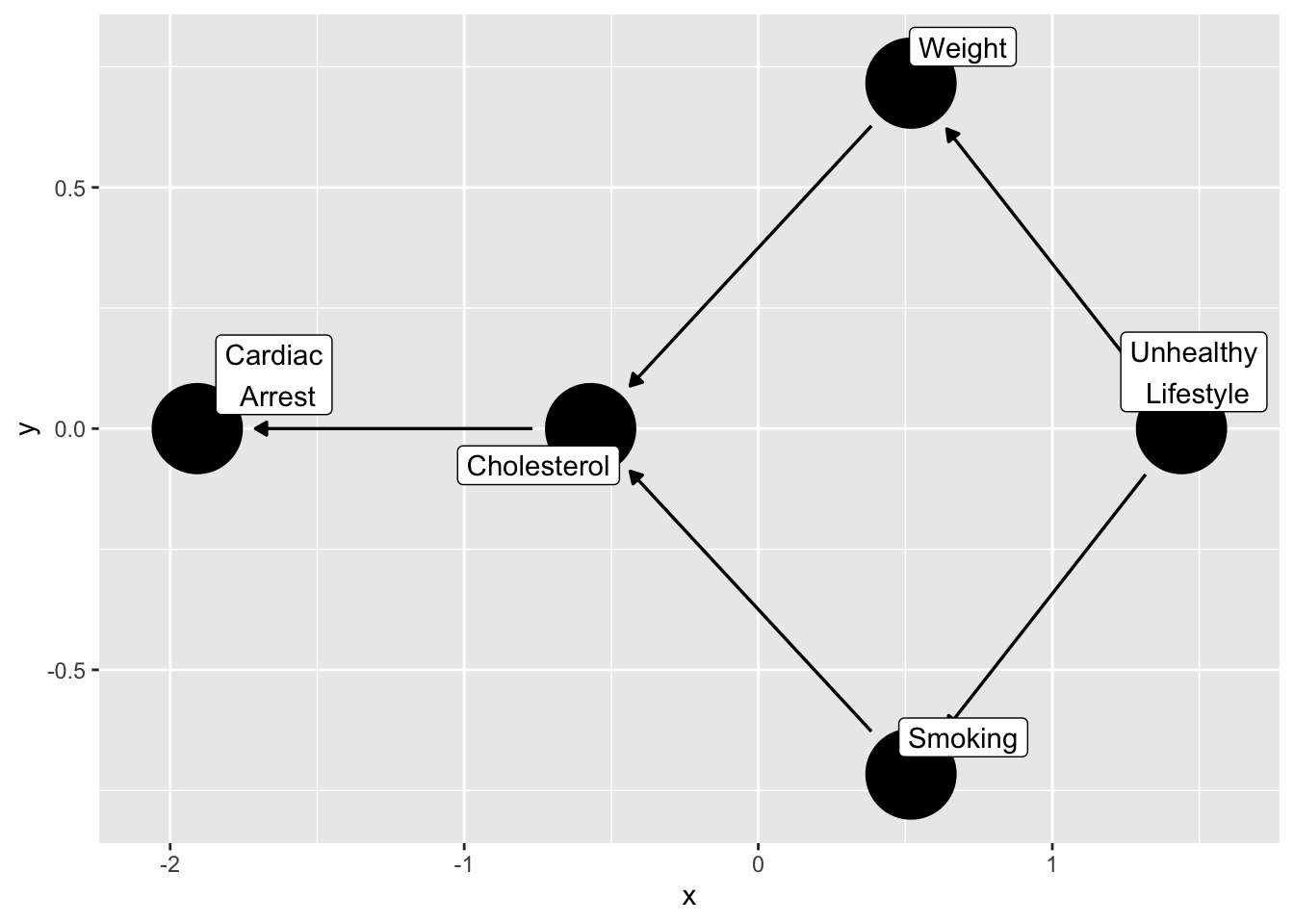
### What is the relationship between smoking and cardiac arrest?
This example is from the `ggdag` package, by Malcolm Barrett [here](https://ggdag.malco.io/)
```{r}
smoking_ca_dag <- dagify(
cardiacarrest ~ cholesterol,
cholesterol ~ smoking + weight,
smoking ~ unhealthy,
weight ~ unhealthy,
labels = c(
"cardiacarrest" = "Cardiac\n Arrest",
"smoking" = "Smoking",
"cholesterol" = "Cholesterol",
"unhealthy" = "Unhealthy\n Lifestyle",
"weight" = "Weight"
),
latent = "unhealthy",
exposure = "smoking",
outcome = "cardiacarrest"
)
ggdag(smoking_ca_dag,
text = FALSE,
use_labels = "label")
```
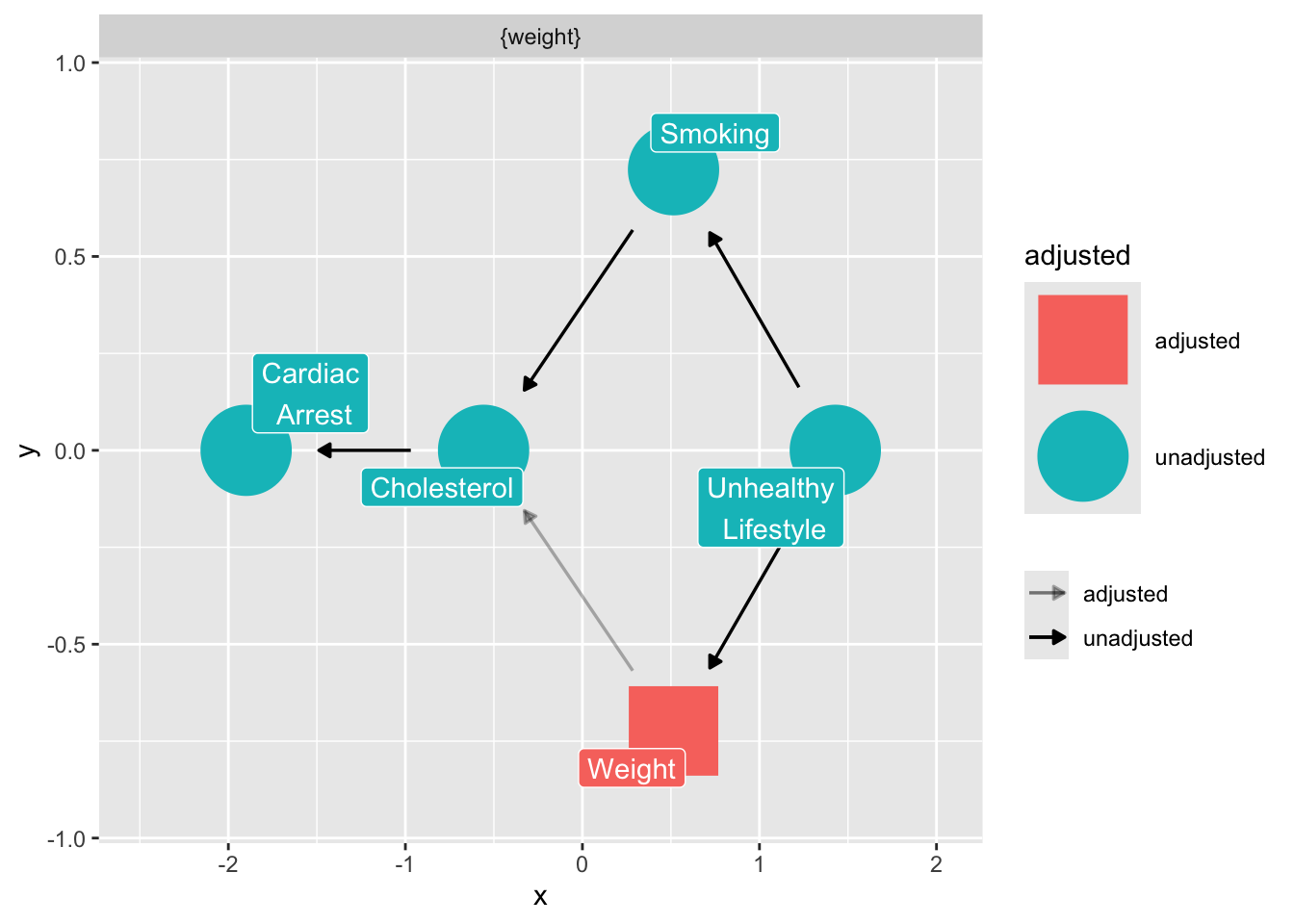
What do we condition on to close any open backdoor paths, while avoiding colliders? We imagine that unhealthy lifestyle is unmeasured.
```{r}
ggdag_adjustment_set(
smoking_ca_dag,
text = FALSE,
use_labels = "label",
shadow = TRUE
)
```
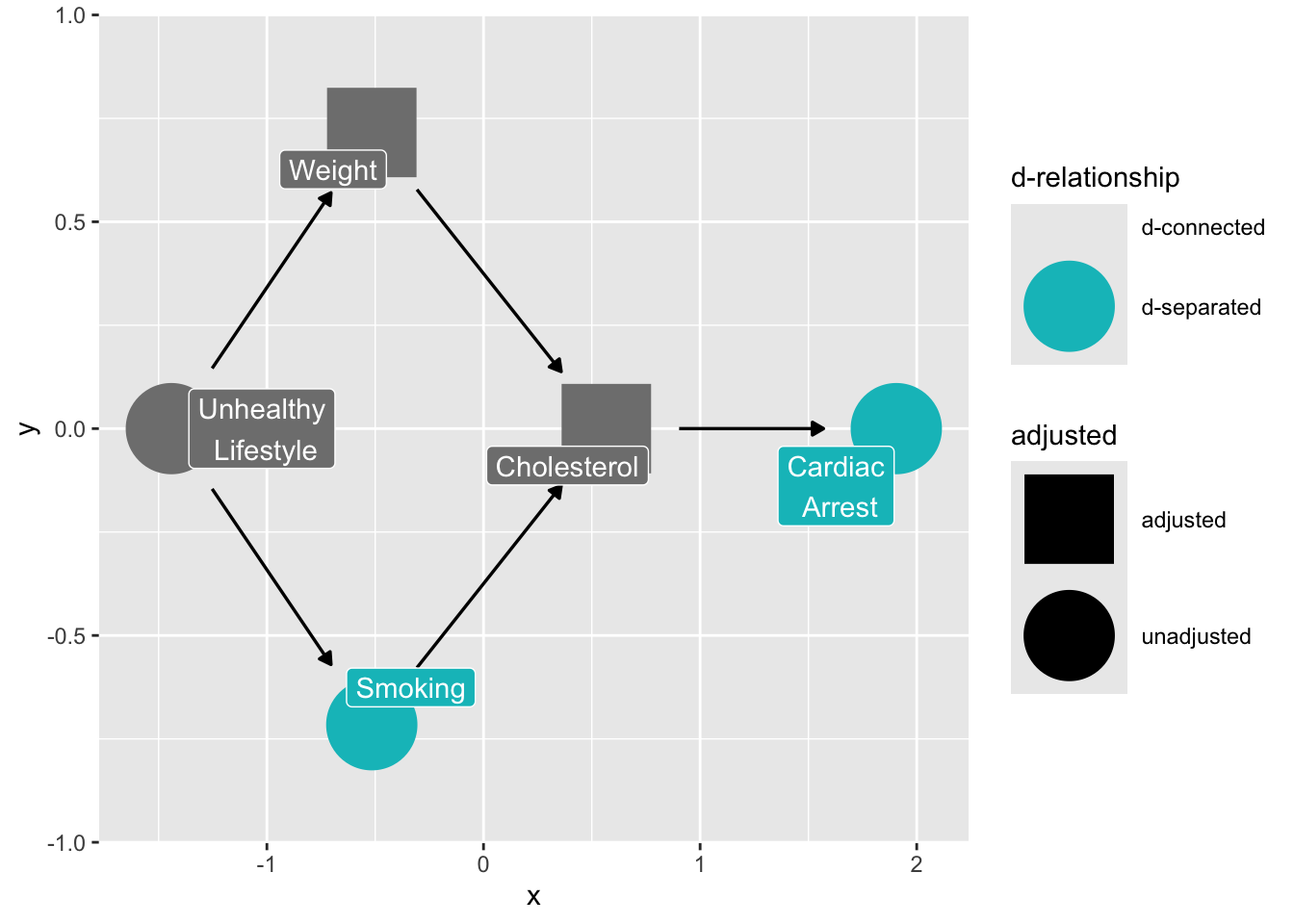
What if we control for cholesterol?
```{r}
ggdag_dseparated(
smoking_ca_dag,
controlling_for = c("weight", "cholesterol"),
text = FALSE,
use_labels = "label",
collider_lines = FALSE
)
```
> Controlling for intermediate variables may also induce bias, because it decomposes the total effect of x on y into its parts. (ggdag documentation)
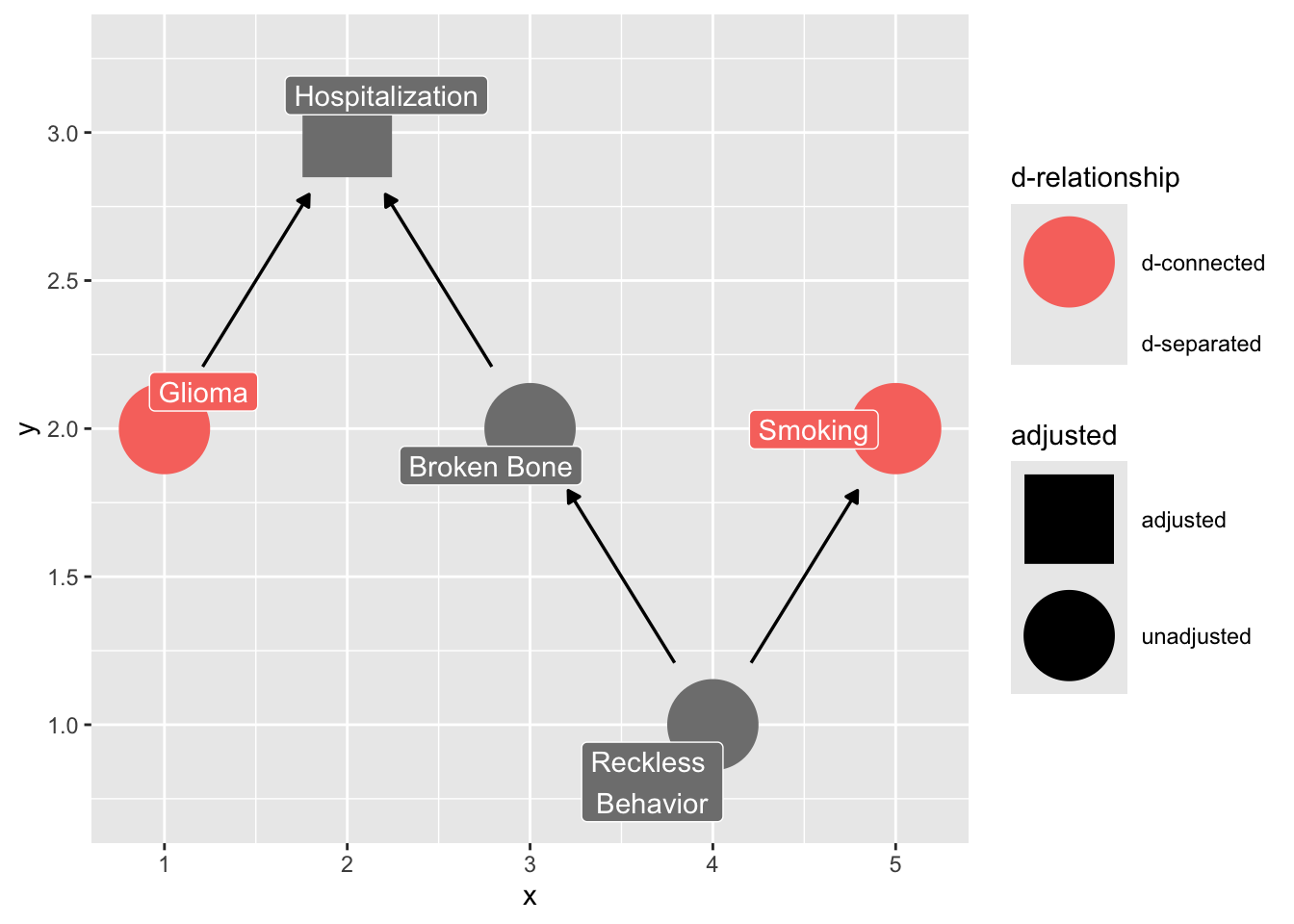
### Selection bias in sampling
This example is from <https://ggdag.malco.io/articles/bias-structures.html>
> Let's say we're doing a case-control study and want to assess the effect of smoking on glioma, a type of brain cancer. We have a group of glioma patients at a hospital and want to compare them to a group of controls, so we pick people in the hospital with a broken bone, since that seems to have nothing to do with brain cancer. However, perhaps there is some unknown confounding between smoking and being in the hospital with a broken bone, like being prone to reckless behavior. In the normal population, there is no causal effect of smoking on glioma, but in our case, we're selecting on people who have been hospitalized, which opens up a back-door path:
```{r}
coords_mine <- tibble::tribble(
~name, ~x, ~y,
"glioma", 1, 2,
"hospitalized", 2, 3,
"broken_bone", 3, 2,
"reckless", 4, 1,
"smoking", 5, 2
)
dagify(hospitalized ~ broken_bone + glioma,
broken_bone ~ reckless,
smoking ~ reckless,
labels = c(hospitalized = "Hospitalization",
broken_bone = "Broken Bone",
glioma = "Glioma",
reckless = "Reckless \nBehavior",
smoking = "Smoking"),
coords = coords_mine) |>
ggdag_dconnected("glioma", "smoking", controlling_for = "hospitalized",
text = FALSE, use_labels = "label", collider_lines = FALSE)
```
> Even though smoking doesn't actually cause glioma, it will appear as if there is an association. Actually, in this case, it may make smoking appear to be protective against glioma, since controls are more likely to be smokers.
### Selection bias in longitudinal research
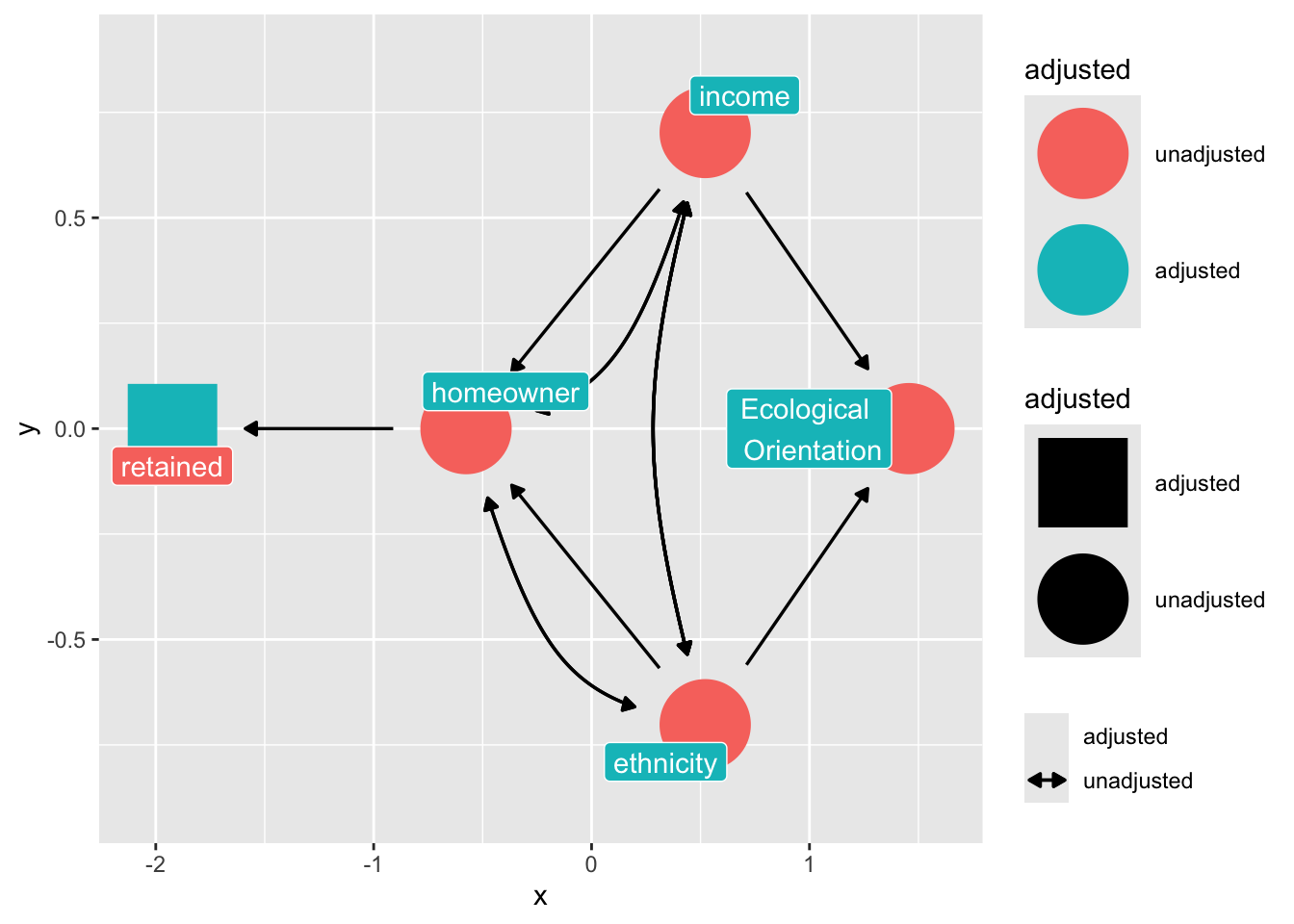
Suppose we want to estimate the effect of ethnicity on ecological orientation in a longitudinal dataset where there is selection bias from homeownership (it is easier to reach homeowners by the mail.)
Suppose the following DAG:
```{r}
dag_sel <- dagify(
retained ~ homeowner,
homeowner ~ income + ethnicity,
ecologicalvalues ~ ethnicity + income,
labels = c(
retained = "retained",
homeowner = "homeowner",
ethnicity = "ethnicity",
income = "income",
ecologicalvalues = "Ecological \n Orientation"
),
exposure = "ethnicity",
outcome = "ecologicalvalues"
) |>
control_for("retained")
dag_sel |>
ggdag_adjust(
"retained",
layout = "mds",
text = FALSE,
use_labels = "label",
collider_lines = FALSE
)
```
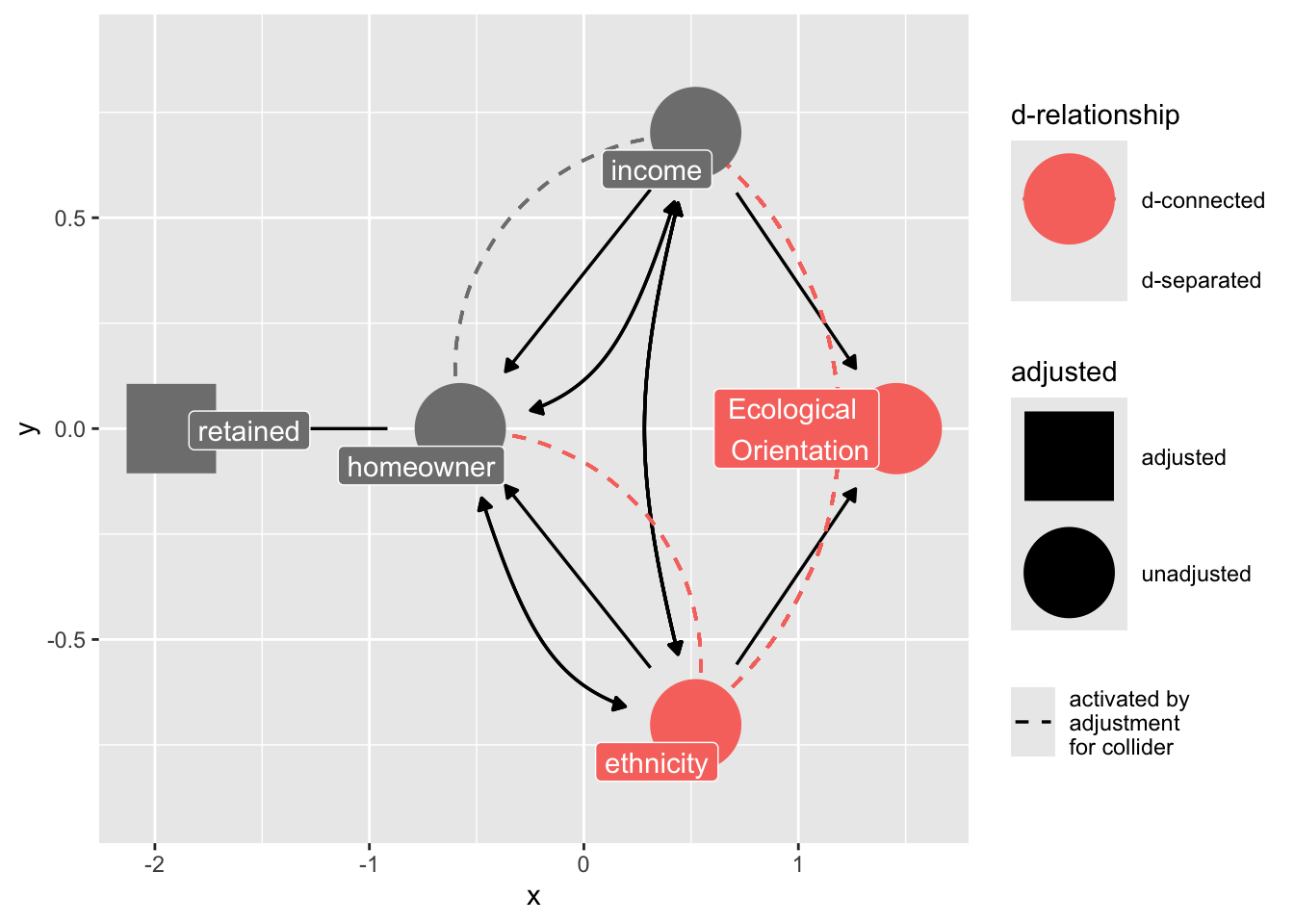
Notice that "retained" falls downstream from a collider, "home ownership"
```{r}
ggdag_collider(dag_sel)
```
Because we are stratifying on "retained", we introduce collider bias in our estimate of ethnicity on ecological values.
```{r}
ggdag_dseparated(
dag_sel,
controlling_for = "retained",
text = FALSE,
use_labels = "label",
collider_lines = TRUE
)
```
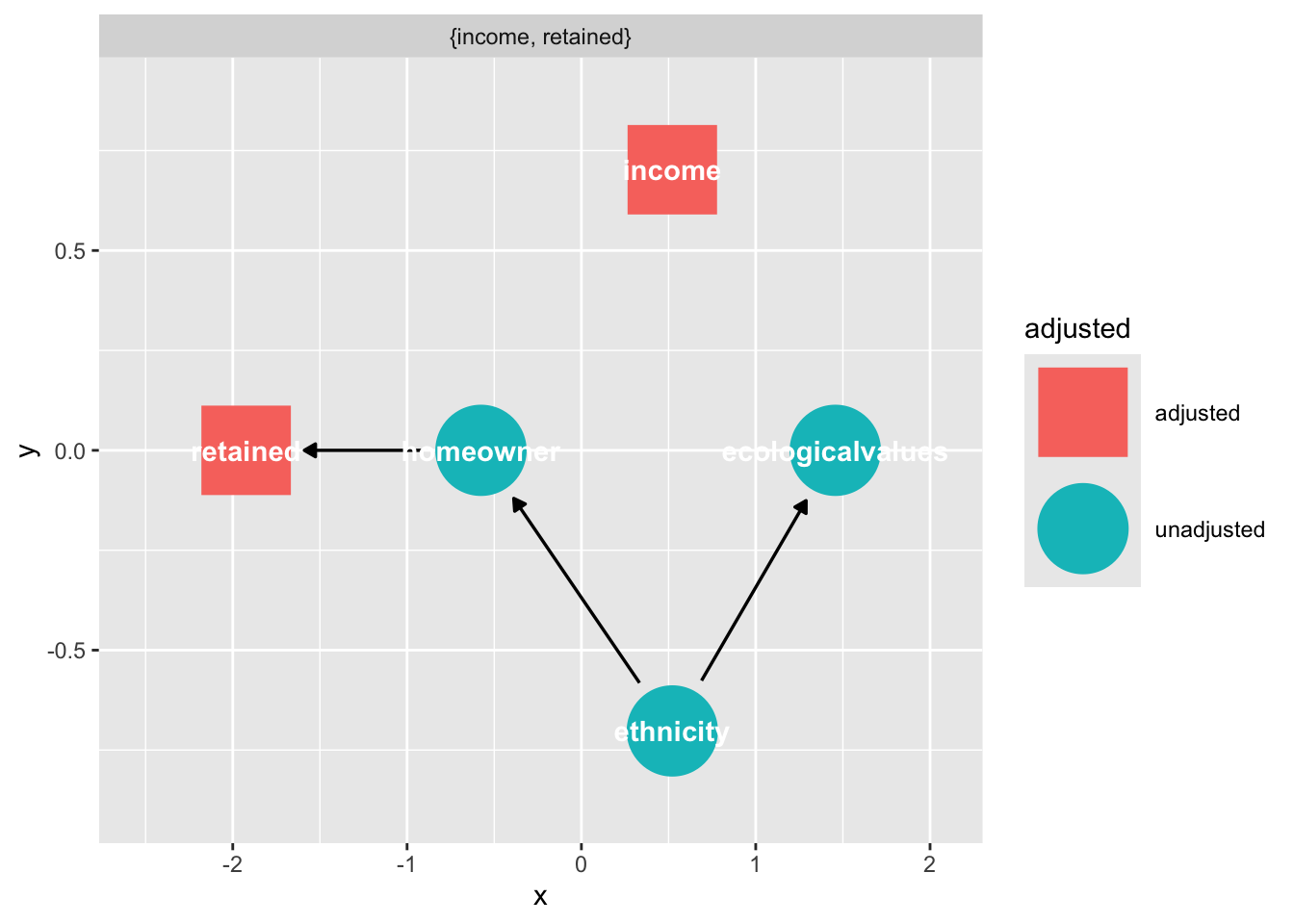
However we have an adjustment set
```{r}
ggdag_adjustment_set(dag_sel)
```
## Workflow
1. Import your data
2. Check that data types are correct
3. Graph your data
4. Consider your question
5. If causal, draw your DAG/S
6. Explain your DAG's
7. Write your model
8. Run your model
9. Graph and interpret your results
10. Return to your question, and assess what you have learned.
(Typically there are multiple iterations between these steps in your workflow. Annotate your scripts; keep track of your decisions)
## Summary
- We control for variables to avoid omitted variable bias
- Omitted variable bias is real, but also commonplace is included variable bias
- Included variable biases arise from "pipes", "colliders", and conditioning on descendant of colliders.
- The `ggdag` package can help you to obtain causal inference, but it relies on assumptions that are not part of your data.
- Clarify your assumption.
### Packages
```{r}
report::cite_packages()
```
#### OTHER MATERIAL:
Selection bias is commonplace.
## Collider bias within experiments
We noted that conditioning on a post-treatment variable can induce bias by blocking the path between the experimental manipulation and the outcome. However, such conditioning can open a path even when there is no experimental effect.
```{r code_folding = TRUE}
dag_ex2 <- dagify(
C1 ~ C0 + U,
Ch ~ U + R,
labels = c(
"R" = "Ritual",
"C1" = "Charity-post",
"C0" = "Charity-pre",
"Ch" = "Cohesion",
"U" = "Religiousness (Unmeasured)"
),
exposure = "R",
outcome = "C1",
latent = "U"
) |>
control_for(c("Ch","C0"))
dag_ex2 |>
ggdag( text = FALSE,
use_labels = "label")
```
How do we avoid collider-bias here?
Note what happens if we condition on cohesion?
```{r}
dag_ex2 |>
ggdag_collider(
text = FALSE,
use_labels = "label"
) +
ggtitle("Cohesion is a collider that opens a path from ritual to charity")
```
Don't condition on a post-treatment variable!
```{r}
dag_ex3 <- dagify(
C1 ~ C0,
C1 ~ U,
Ch ~ U + R,
labels = c(
"R" = "Ritual",
"C1" = "Charity-post",
"C0" = "Charity-pre",
"Ch" = "Cohesion",
"U" = "Religiousness (Unmeasured)"
),
exposure = "R",
outcome = "C1",
latent = "U"
)
ggdag_adjustment_set(dag_ex3)
```
## Taxonomy of confounding
There is good news. Remember, ultimately are only four basic types of confounding:
### The Fork (omitted variable bias)
```{r}
confounder_triangle(x = "Coffee",
y = "Lung Cancer",
z = "Smoking") |>
ggdag_dconnected(text = FALSE,
use_labels = "label")
```
### The Pipe (fully mediated effects)
```{r}
mediation_triangle(
x = NULL,
y = NULL,
m = NULL,
x_y_associated = FALSE
) |>
tidy_dagitty(layout = "nicely") |>
ggdag()
```
### The Collider
### Confounding by proxy
If we "control for" a descendant of a collider, we will introduce collider bias.
```{r}
dag_sd <- dagify(
Z ~ X,
Z ~ Y,
D ~ Z,
labels = c(
"Z" = "Collider",
"D" = "Descendant",
"X" = "X",
"Y" = "Y"
),
exposure = "X",
outcome = "Y"
) |>
control_for("D")
dag_sd |>
ggdag_dseparated(
from = "X",
to = "Y",
controlling_for = "D",
text = FALSE,
use_labels = "label"
) +
ggtitle("X --> Y, controlling for D",
subtitle = "D induces collider bias")
```